Tokenizer
复制本地路径 | 在线编辑
其实就是把用户输入的文本切成 token 的这一个过程。
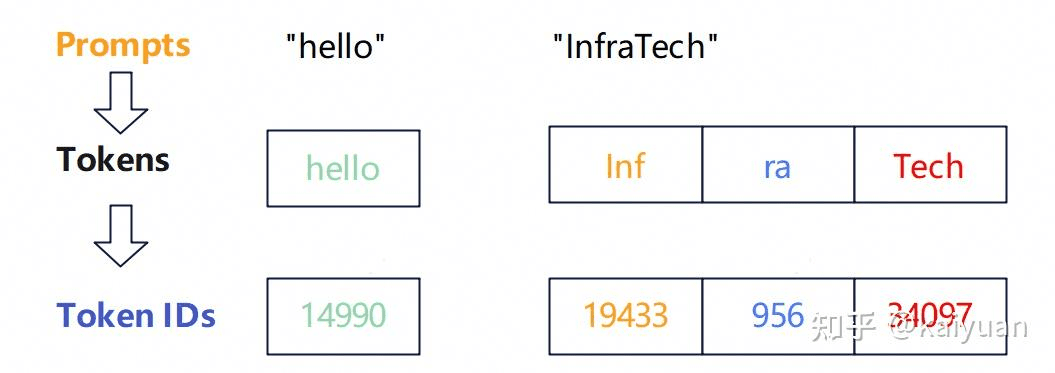
Tokenizer(分词器)负责把用户输入的文本切成 token,再映射成模型能直接计算的 token ID(整数序列)。换句话说:模型读到的并不是原始字符串,而是「分词 + 编号」之后的结果;因此 tokenizer 是推理与训练里最先接触的一层。
同一段 prompt 在送进 LLM 之前必须先经 tokenizer 编码;最终得到的 token 个数以及每个位置上的 ID,取决于具体分词器及其实现与配置(词表、归一化规则、是否合并子词等)。以 Qwen3 的分词器为例,下面词组经编码后会得到不同的切分:例如 "hello" 只对应 1 个 ID,而 "InfraTech" 则被拆成 3 个 ID。