Paged Attention
参考文章:https://zhuanlan.zhihu.com/p/1999536171961828862
非常好的文章,很多文章没看懂,但是这篇很快就让人理解了。非常推荐看原文。
前提知识
[[KV-Cache]]
背景介绍
在 Attention 中用到的 K 和 V,为了避免重复计算这些历史 Key 和 Value 向量,推理系统通常会将它们缓存下来,称为 KV Cache(Key-Value 缓存)。这不仅节省了大量重复计算,也显著提升了推理效率。
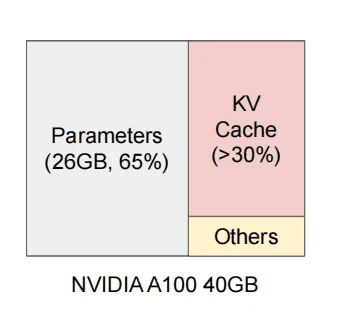
但是 KV Cache 很占显存,下图展示了一个 13B 参数规模的大语言模型在 NVIDIA A100 40GB 显存 GPU 上推理时的显存使用分布。其中:
- Parameters(26GB, 65%):指模型的权重参数,这部分在加载模型后常驻显存,大小固定;
- KV Cache(>30%):用于存储每个请求的历史 Key 和 Value 向量,随着生成 token 数量动态增长,是最主要的动态内存开销来源;
- Others:主要指推理过程中暂时产生的中间计算结果(如 activation),生命周期短,通常在计算完一层后即被释放,占用较少。
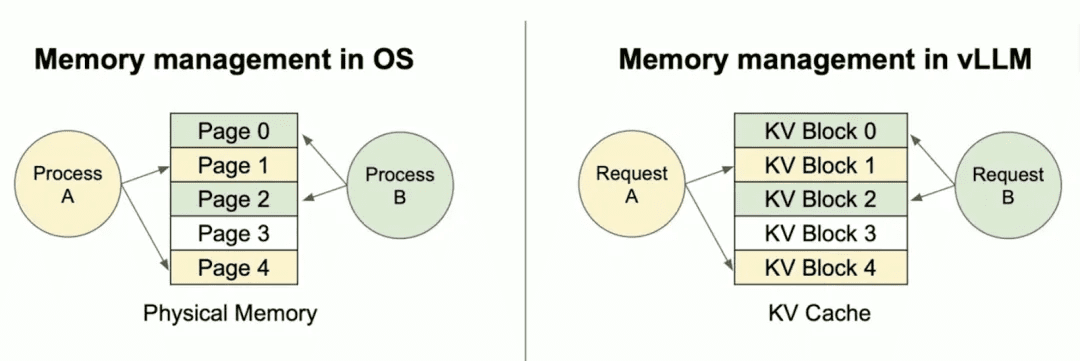
之前的问题
之前没怎么管理 KV Cache,所以导致有很多显存浪费,主要有三种:
- 已预留但尚未使用的空间(Reserved):虽然未来会使用,但当前暂未使用到。
- 内部碎片(Internal Fragmentation):实际 token 数小于预留长度,剩余空间浪费。
- 外部碎片(External Fragmentation):不同请求所需内存大小不一,造成内存块间不连续,产生碎片。

Paged Attention
Paged Attention 的核心思想,借鉴自操作系统中广泛应用的虚拟内存分页机制。
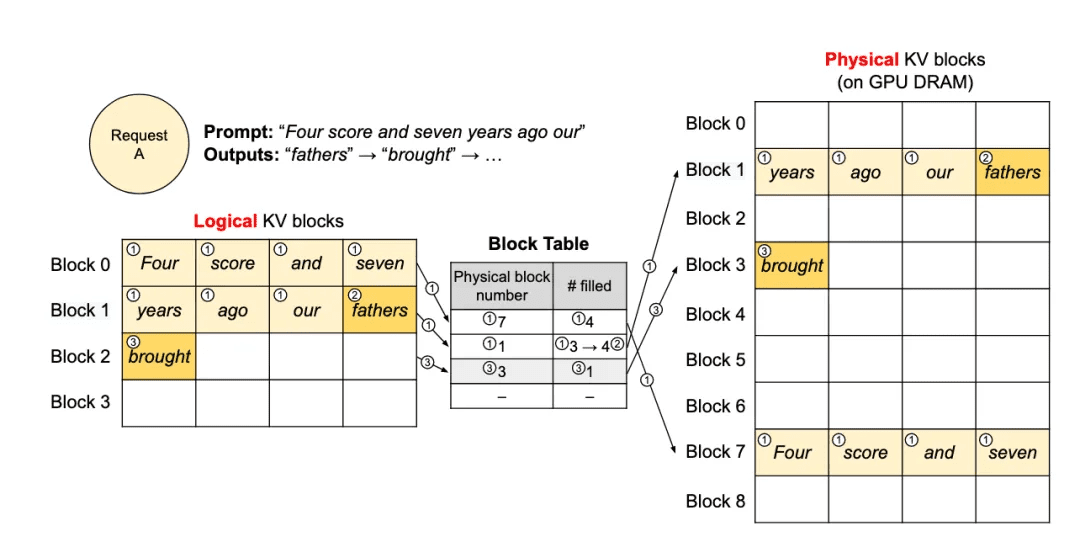
如下图所示,用户请求的 prompt 为 "Four score and seven years ago our",共包含 7 个 token:
- prefill 阶段:vLLM 为前 7 个 token 分配两个逻辑块 block 0 和 block 1,分别映射到物理块 7 和 1。block 0 存储前 4 个 token,block 1 存储后 3 个 token 及第一个生成 token
"fathers",填充数为 4。 - decode 阶段 - 生成第 1 个词:生成 token
"brought",由于 block 1 尚未填满(最多容纳 4 个 token),因此直接将新 KV Cache 写入该块,填充计数从 3 更新为 4。 - decode 阶段 - 生成第 2 个词:生成下一个 token,此时 block 1 已满,系统为逻辑块 block 2 分配新的物理块 block 3,并写入 KV Cache,同时更新映射表。
整个过程中,每个逻辑块仅在前一个块被填满后才会分配新的物理块,从而最大程度地减少内存浪费。不难发现,在计算时我们操作的是逻辑块,也就是说,这些 token 在形式上是连续排列的;与此同时,vLLM 会通过 block table 映射关系,在后台将逻辑块映射到实际的物理块,从而完成数据的读取与计算。通过这种方式,每个请求仿佛都在一个连续且充足的内存空间中运行,尽管这些数据在物理内存中实际上是非连续存储的。
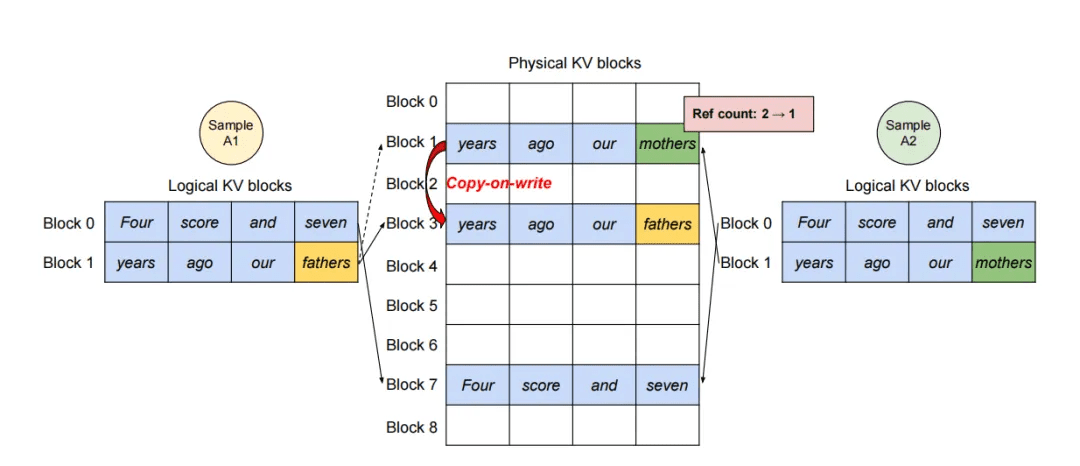
而且,由于这种技术,可以实现复用,只需要逻辑块指向同一个物理块就可以。在 LLM 中,通常有很多场景下多个响应的前缀是一样的。
- 并行采样(Parallel Sampling)
在 Parallel Sampling 中,同一个 prompt 会生成多个候选输出,便于用户从多个备选中选择最佳响应,常用于内容生成或模型对比测试。
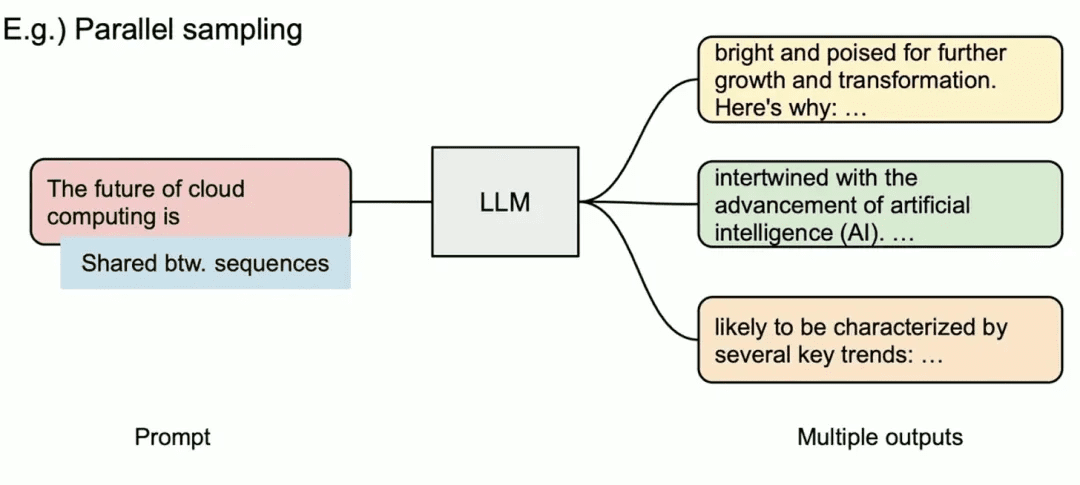
在 vLLM 中,这些采样序列共享相同的 prompt,其对应的 KV Cache 也可以共用同一组物理块。PagedAttention 通过引用计数和 block-level 的 copy-on-write 机制实现共享与隔离的平衡:只有当序列出现不同分支时,才会触发复制操作。
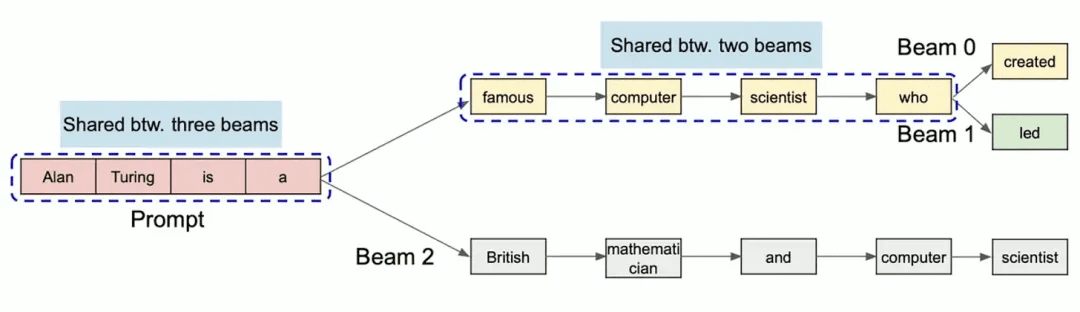
- 束搜索(Beam Search)
Beam Search 是一种解码策略,如果不懂也可以先不管,直接看下面的图,总之都是可以复用的场景。只要这些 beam 的生成路径尚未分叉,它们就会复用相同的物理块。当路径分叉发生后,vLLM 才通过 copy-on-write 机制对共享块进行拆分,从而保证每个 beam 的独立性。
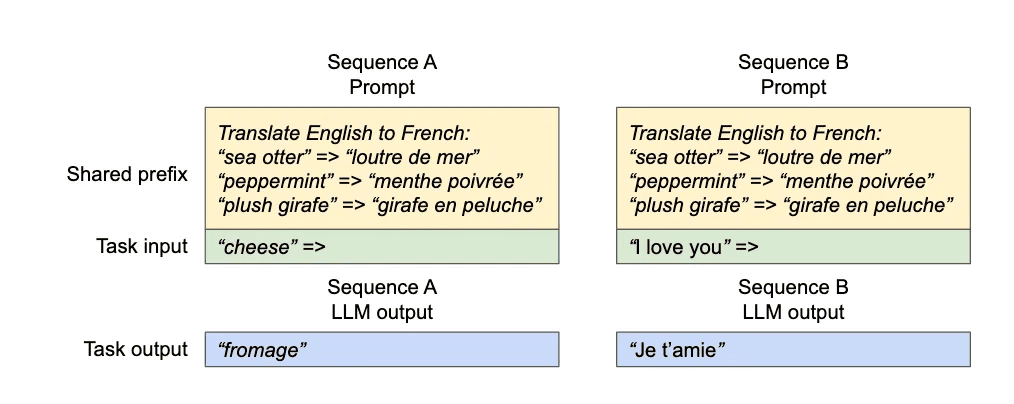
- 共享前缀(Shared Prefix)
在许多提示工程实践中,多个请求会以相同的系统提示或 few-shot 示例开头(例如翻译任务中的多个例句)。这些共享前缀同样可以被 vLLM 缓存并复用。