硬件学习:NVLink 和 NVSwitch
从 PCIE 到 NVLink
PCIE 想必不用多说,英特尔牵头设计,许多硬件都是插在 PCIE 插槽上,然后进行通信的。但是他有一个严重的问题:
GPU显存的速度快但容量小,CPU内存的速度慢但容量大。因为内存系统的差异,加速的计算应用一般先把数据从网络或磁盘移至CPU内存,然后再复制到GPU显存,数据才可以被GPU处理。
GPU 需要通过 PCIe 接口连接至CPU,但 PCIe 接口太落后,限制了GPU存取CPU系统内存的能力,对比CPU内存系统要慢4-5倍。
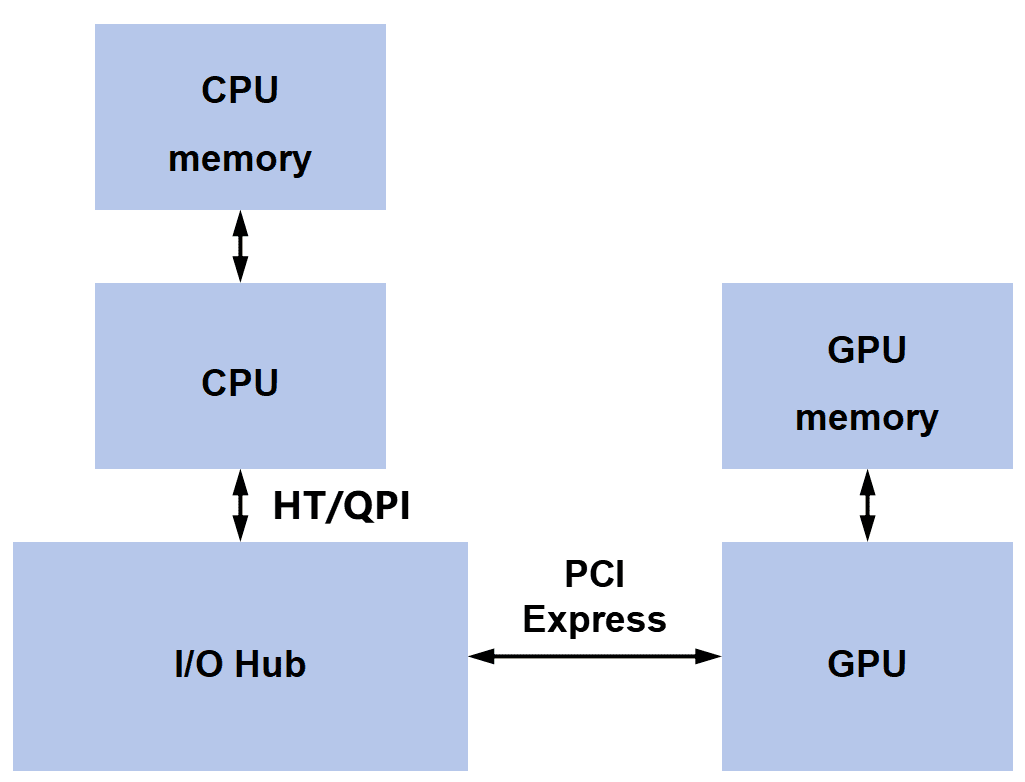
所以英伟达就自行设计了 NVLink 技术,有了NVLink之后,NVLink接口可以和一般CPU内存系统的带宽相匹配,让GPU以全带宽的速度存取CPU内存,解决了CPU和GPU之间的互联带宽问题,从而大幅提升系统性能。
NVLink 为什么快
具体的细节不谈了,看最开始推荐的文章。总之NVLink是一种基于高速差分信号线的串行通信技术。
很显然,连接肯定是需要专门的硬件,PICe 要 PICE 卡槽,那 NVLink 则是 NVLink Bridge

两张卡和四张卡都可以两两相连。八张卡则有点区别,在HGX-1系统中实现了一种 “hybrid cube mesh” 8 GPU互联结构。如下图所示:
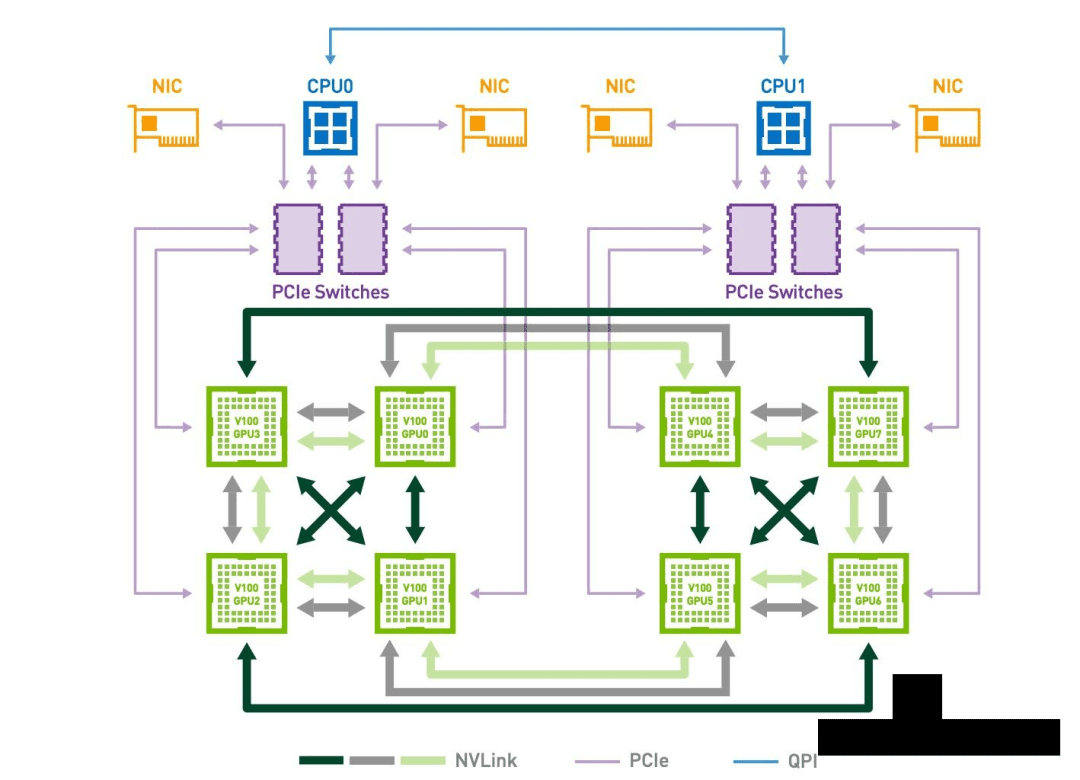
每一块GPU都巧妙利用了其6条NVLink,与其他4块GPU相连。8块GPU以有限的NVLink数量,实现了整体系统的最佳性能。
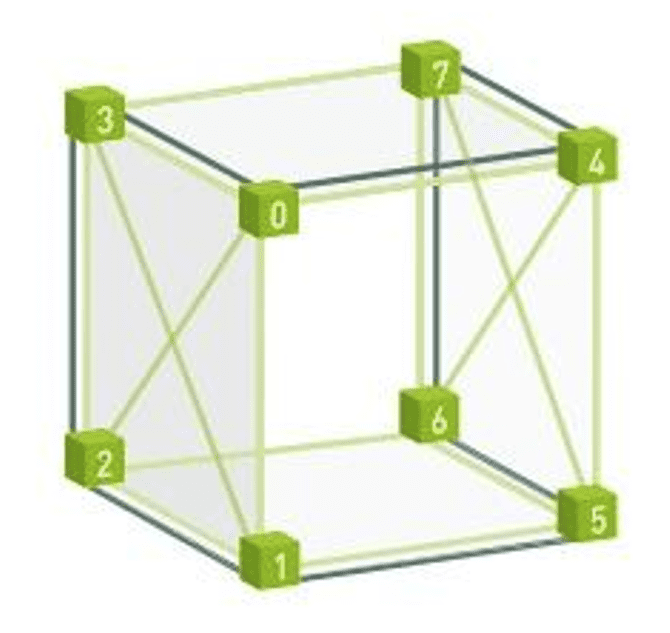
这个图看上去有点奇怪。实际上,如果把它以立体的方式呈现,就很清晰了:
NVSwitch
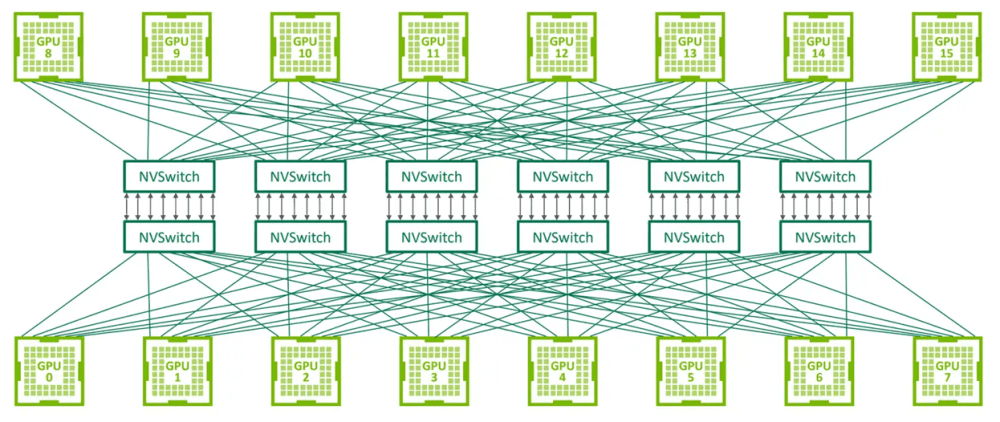
2018年,为了实现8颗GPU之间的all-to-all互连,英伟达发布了NVSwitch 1.0。
NVSwitch,说白了就是“交换芯片”。它拥有18个端口,每个端口的带宽是50GB/s,双向总带宽900GB/s。用6个NVSWitch,可以实现8颗V100的all-to-all连接。
引入NVSwitch的DGX-2,相比此前的DGX-1,提升了2.4倍的性能。
到NVLink 4.0的时候,DGX的内部拓扑结构增加了NVSwitch对所有GPU的全向直连,DGX内部的互联结构得到简化。
之后英伟达还再不断更新,不断推出新的通信技术。这里就不讲了。