基于策略
新方法的引入
前面介绍许多的方法,这些方法都是基于价值的方法,也就是智能体需要通过价值函数(如 Q 函数)评估每个动作的价值,然后选择最优动作。对于连续动作空间,动作是无限多的,无法像离散动作空间那样枚举所有可能的动作并计算其价值。非要算也可以,一种常见的解决方法是离散化连续动作空间,但这会带来很多新的问题,如离散化的粒度如何确定、维度灾难等等……
下面通过一个例子来说明这样的情况,对于机器人运动而言,我们关注其中的一个关节,状态 s 表示当前关节角度和当前速度,现在我们需要知道下一个动作是什么。如果拆分成离散:
关节角度为 0~360,每 1 度拆分,这样就有拆成 36 个离散档位,即总动作数为 36 个;一个关节这样,两个关节就 \(36^2\),三个关节就更多,我们是这样选择动作的:
那也就是说,我们需要每次都遍历天文数字的动作情况,然后从中选择最大值,确定出动作。就是为什么拆分成离散并不可以。
由此引入了新的思想:基于策略,它不考虑什么价值,而是直接对策略 \(\pi\) 进行预测,即传入状态 s,直接传入 \(\pi_\theta(s)\) 得到动作,其中 \(\theta\) 是参数。按照上面的例子,输入当前状态 s,输出得到关节角度。不仅没有维度爆炸,而且输出的是自然数,比拆分离散也更顺畅。
真实情况的解释
不过实际情况中往往不是直接输出动作,输出的是它输出的是连续概率分布的参数,它输出的是连续概率分布的参数,最常用:高斯分布。
网络输入:状态 \(s\)
网络输出两个向量:
- \(\boldsymbol{\mu}(s)\):高斯均值 → 代表最推荐的最优动作
- \(\boldsymbol{\sigma}(s)\):高斯方差 → 代表探索的随机程度
神经网络算出:\(\mu, \sigma\) 后,从这个高斯分布里采样一个连续动作:
把这个实数 \(a\) 发给电机:输出力矩/转动角度。
为什么要输出两个值,而不是直接输出动作 a
直接来自 AI 的回答
这是强化学习最核心、最本质、最颠覆直觉的问题,我用大白话 + 致命理由给你讲透,彻底打通你所有疑惑。
先回答你的直击灵魂问题:
能不能让网络直接输出一个确定动作 \(a\)?
能。完全可以。
这就是 确定性策略。
代表算法:DDPG、TD3
网络直接输出:
[
a = \mu_\theta(s)
]
没有高斯、没有概率、没有采样,直接给一个固定动作。
那为什么全世界 90% 的 PPO / PG / SAC 非要搞:
输出 \(\mu,\sigma\) → 高斯分布 → 采样动作 → 算 \(\log\pi(a|s)\)?
因为:纯确定性策略,有一个绝症:不会探索,必死。
核心原因 1:环境不知道好坏,必须靠「随机」试探
1. 纯确定性策略(直接输出 a)
看见状态 \(s\),永远只做同一个动作。
- 永远左转、永远用力矩 0.5、永远同一种走位
- 哪怕这条路奖励很低、是死胡同,它一辈子不会换动作
- 完全没有探索能力,直接锁死局部最优
2. 随机策略(高斯概率)
同一个状态 \(s\):
- 大部分时间走最优动作(利用)
- 偶尔随机飘一点,试试别的动作(探索)
只有随机,才能试探未知行为,找到更高奖励。
核心原因 2:策略梯度数学上,必须要有概率密度
这是硬数学约束,绕不开。
策略梯度核心公式:
[
\nabla_\theta J = \mathbb{E}\Big[ \nabla_\theta \log \pi_\theta(a|s) \cdot A(s,a) \Big]
]
你发现没?
必须要有 \(\boldsymbol{\log \pi(a|s)}\) 这一项。
- \(\pi(a|s)\) = 选中这个动作的概率/概率密度
- 如果是确定性策略:
\(\pi(a|s)=1\),\(\log 1 = 0\)
→ 梯度直接消失,参数永远不更新,学不动
✅ 解决方案:
必须是随机策略,让每一个动作都有一个「被选中的概率打分」,
才能算出梯度、才能更新网络、才能学习。
核心原因 3:现实世界最优动作本来就不是唯一的
回到你最开始的例子:机器人关节
同一个角度状态 \(s\):
- 力矩 0.21 很好
- 力矩 0.23 也很好
- 差别极小,都是优质解
确定性策略
强行只选一个:0.22
硬生生丢掉一堆可行优质动作,鲁棒性极差。
高斯随机策略
以最优为中心,一整片区间都是高概率:
轻微扰动、机械误差、环境变化,全都能扛住。
控制器更稳、更鲁棒、更像生物。
核心原因 4:随机性可以控制强度(动态调节探索)
网络可以动态学习方差 \(\sigma(s)\):
- 前期不懂环境:\(\sigma\) 很大 → 大范围瞎试
- 后期熟练收敛:\(\sigma\) 自动变小 → 动作越来越确定、平稳
纯确定性策略
全程一成不变,没法动态调节探索强度。
终极总结:两条路线并存,各有分工
路线 A:确定性策略(直接输出动作 a)
代表:DDPG、TD3
- 无概率、无采样
- 依赖外部加噪声强行探索
- 适合:仿真控制、环境简单、不需要复杂探索
路线 B:随机策略(输出高斯分布,采样 a)
代表:PPO、A2C、SAC、原始策略梯度
- 内部自带概率分布,原生自带探索
- 梯度完整、训练更稳、泛化更强
- 适合:复杂环境、多模态行为、博弈、真实机器人
给你一句一秒记住的人话
- 直接输出动作 = 死板、不会试探、学不远
- 输出概率分布 = 学会择优 + 主动试探 + 能算梯度更新
需要我给你画一个极简对比:
「确定性策略」vs「随机高斯策略」
同一个状态下的行为差异,一眼看懂吗?
为什么是高斯分布
以下是 AI 的回答:
直接给你行业真相 + 分类结论,精准回答:
一、结论
-
所有 连续动作任务(机器人、电机、自动驾驶、机械臂、四足、力矩控制)
✅ 95% 默认就是高斯分布
PPO / A2C / DDPG / TD3 / SAC 连续版本,原生标配对角高斯。 -
所有 离散动作任务(游戏、Atari、格子世界)
❌ 不用高斯
用:Categorical 类别分布(你理解的:每个动作一个概率)。
二、为什么连续几乎全是高斯?
前面说过的关键点浓缩:
- 连续动作需要:一个最优中心 + 周围平滑探索,高斯天然长这样。
- \(\log \mathcal N\) 解析式简单、求导极稳,策略梯度、Actor 网络好训练。
- 多维动作直接对角高斯分解,维度线性增加,不爆炸。
- 配合
tanh约束范围,完美适配电机/力矩限位。
三、有没有「不用高斯」的连续策略?
有,但极少用、小众、特定场景:
1. 拉普拉斯分布
- 特点:尖峰、厚尾,更容易探索极端动作
- 用途:少量需要激进探索的场景
- 现状:主流算法几乎不用
2. Beta 分布
- 天生有界 \([0,1]\),不用 tanh 截断
- 缺点:梯度更复杂、训练更难调
- 用途:一些小众机器人、无人机论文
3. 混合高斯、复杂流式分布
- 多峰策略,适合有多个最优动作的场景
- 缺点:参数暴增、极难收敛
- 工业落地基本不用
四、关键区分:你容易混淆的两个流派
① 价值派:DQN 家族
- 离散:Categorical 打分
- 连续:天生不能用,必须改成 DDPG/TD3 演员 - 评论家
② 策略派:PG/PPO/SAC 家族
- 离散 → Categorical
- 连续 → 标准高斯
五、补充一个超重要细节
你会看到一句话:
连续策略用「对角高斯」
意思:
多关节、多维动作,各个维度互相独立,互不影响。
6 轴机械臂:6 个独立一维高斯,简单、稳定、好训。
六、一句话背下来
- 离散动作 ➜ 分类分布 Categorical
- 连续动作 ➜ 对角高斯分布
- 工业/开源框架/主流论文,严格遵守这个定式。
需要我给你对比一张极简对照表:
「离散 Categorical」vs「连续高斯」的网络输出、数学形式、采样方式,一眼彻底分清吗?
第一种简单的方法
我们的目标是最终训练出 \(\pi_\theta\),为了形式化这个目标,我们定义目标函数
其中,\(\tau\) 表示产生的一个轨迹 (trajectory),其由一系列的状态和动作组成,表示为 \({s_0, a_0, s_1, a_1, ..., s_T, a_T}\)。而 \(G(\tau)\) 就是这个轨迹的总回报(total return),即:
这里 \(r_t\) 表示在时刻 t 的奖励。
很自然的,我们对 \(J(\theta)\) 进行求梯度,经过推导,可以得到:
证明过程
以下内容来自:https://datawhalechina.github.io/easy-rl/#/chapter4/chapter4
对符号进行了替换。
因为我们要让奖励越大越好,所以可以使用梯度上升(gradient ascent)来最大化期望奖励。要进行梯度上升,我们先要计算期望奖励 \(J(\theta)\) 的梯度。我们对 \(J(\theta)\) 做梯度运算
其中,只有 \(p_{\theta}(\tau)\) 与 \(\theta\) 有关。
奖励函数\(G(\tau)\) 不需要是可微分的(differentiable),这不影响我们解决接下来的问题。例如,如果在生成对抗网络(generative adversarial network,GAN)里面,\(G(\tau)\) 是一个判别器(discriminator),它就算无法微分,我们还是可以做接下来的运算。
我们可以对 \(\nabla p_{\theta}(\tau)\) 使用式 (4.1),得到 \(\nabla p_{\theta}(\tau)=p_{\theta}(\tau) \nabla \log p_{\theta}(\tau)\)。
接下来,我们可得
注:上式用了对数函数的求导公式,对数函数 \(f(x)=\log x\) 的导数为 \(\frac{1}{x}\)。
如式 (4.2) 所示,我们对 \(\tau\) 进行求和,把 \(G(\tau)\) 和 \(\log p_{\theta}(\tau)\) 这两项使用 \(p_{\theta}(\tau)\) 进行加权,既然使用 \(p_{\theta}(\tau)\) 进行加权,它们就可以被写成期望的形式。也就是我们从 \(p_{\theta}(\tau)\) 这个分布里面采样 \(\tau\) ,去计算 \(G(\tau)\) 乘 \(\nabla\log p_{\theta}(\tau)\),对所有可能的 \(\tau\) 进行求和,就是期望的值(expected value)。
我们用蒙特卡洛的思想,大量采样,然后进行训练。采样 \(N\) 个 \(\tau\),计算每一个的值,把每一个的值加起来,就可以得到梯度,即
第二项 log 的推导过程
注意, \(p(s_1)\) 和 \(p(s_{t+1}|s_t,a_t)\) 来自环境,\(p_\theta(a_t|s_t)\) 来自智能体。\(p(s_1)\) 和 \(p(s_{t+1}|s_t,a_t)\) 由环境决定,与 \(\theta\) 无关,因此 \(\nabla \log p(s_1)=0\) ,\(\nabla \sum_{t=1}^{T}\log p(s_{t+1}|s_t,a_t)=0\)。
说实话上面这段话没太懂,我对 p 的理解可能还是不到位,但是我感觉不用钻牛角尖。当时在这上面花的时间有点多。
顺理成章的,训练 \(\theta\) 的方式就是:
具体的方式,首先固定好参数 \(\theta\),然后去交互,交互完以后,就可以得到大量游戏的数据。记录好每个状态 s 采取了动作 a,多次尝试。根据采集的数据更新模型,然后继续采样,反反复复。
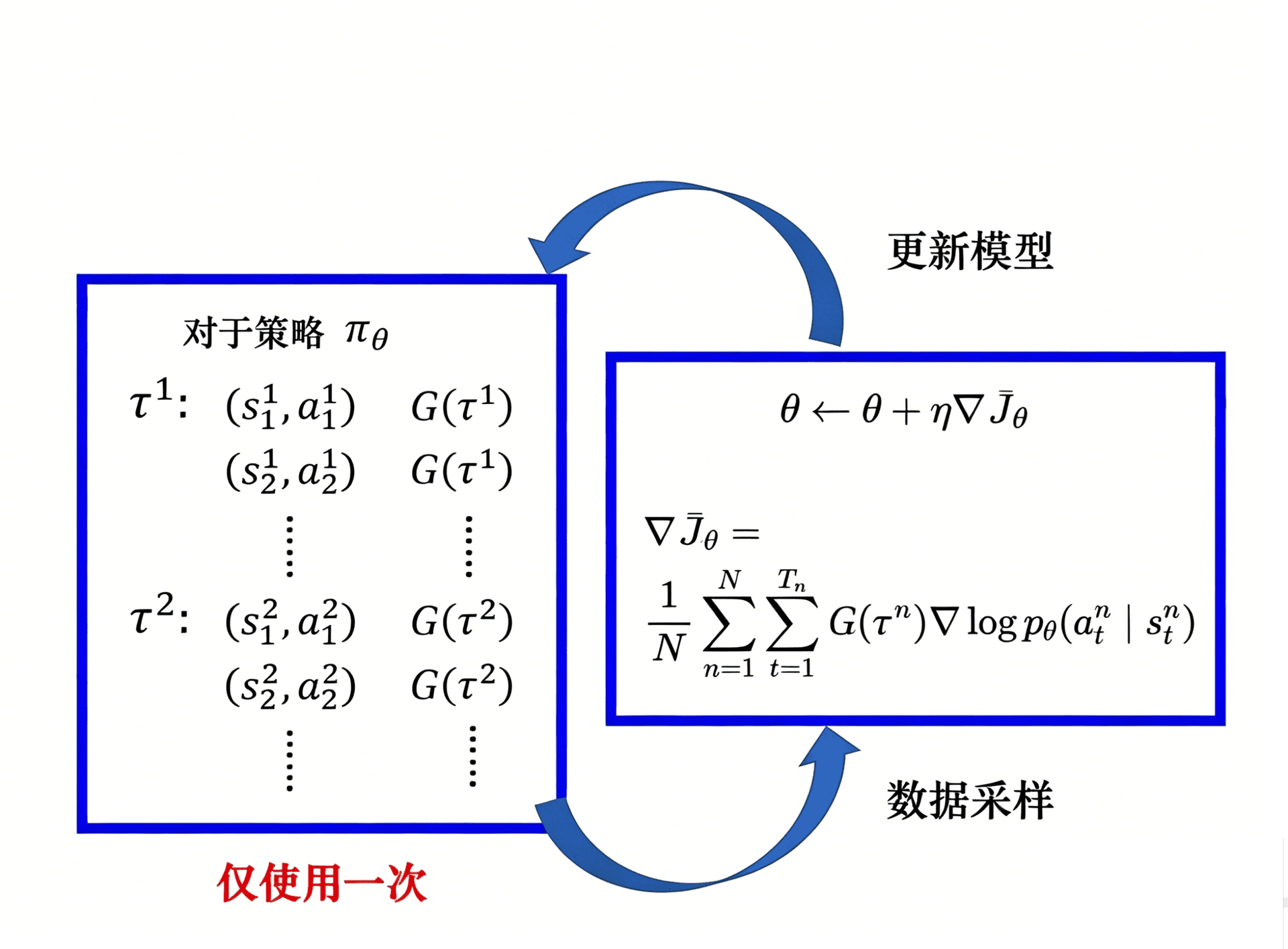
注意,采样的数据只会用一次。我们采样这些数据,然后用这些数据更新参数,再丢掉这些数据。接着重新采样数据,才能去更新参数。
而且其实从公式中也可以看出,本质上就是每对训练数据,乘上一个 \(G(\tau)\) 进行加权,然后就和平常的分类问题一样了,可以直接套用 PyTorch 之类的框架就可以了。
REINFORCE
上一个算法有一个不足,它使用了 \(G(\tau)\) 作为权重,它包含了整个轨迹的回报,也就是说,站在时刻 t 的视角去看,这个总回报既包含了时刻 t 之前的奖励,也包含了时刻 t 之后的奖励。
这不太符合我们的直觉:我们一个朴素的直觉是,当前时刻的动作选择,只应该考虑当前以及未来的奖励,而不应该考虑过去的奖励。所以 REINFORCE 的思想就很简单,就是用 \(G_t\) 代替 \(G(\tau)\),即:
梯度上也就这一处区别,因为其他方面啥也没改:
有个技巧,叫做 添加基线。如果给定状态 \(s\) 采取动作 \(a\),整场游戏得到正的奖励,就要增加 \((s,a)\) 的概率。如果给定状态 \(s\) 执行动作 \(a\),整场游戏得到负的奖励,就要减小 \((s,a)\) 的概率。但在很多游戏里面,奖励总是正的,最低都是 0。比如打乒乓球游戏,分数为 0 ~ 21 分,所以 \(G(\tau)\) 总是正的。
所以很直观咯,用 \(G(\tau)\) 减去一个值就行了,减去一个 \(b\),这个就叫基线。即最终是 \(G(\tau)-b\),可以对 \(G(\tau)\) 的值取期望,计算 \(G(\tau)\) 的平均值,令 \(b \approx E[G(\tau)]\)。
有了基线以后,我们就可以得到最终的梯度: