BWT 编码
复制本地路径 | 在线编辑
简介
直接找的参考资料一的图片,讲的很清晰。总之还是那句话:原理不是关键,用的时候再去看。
编码
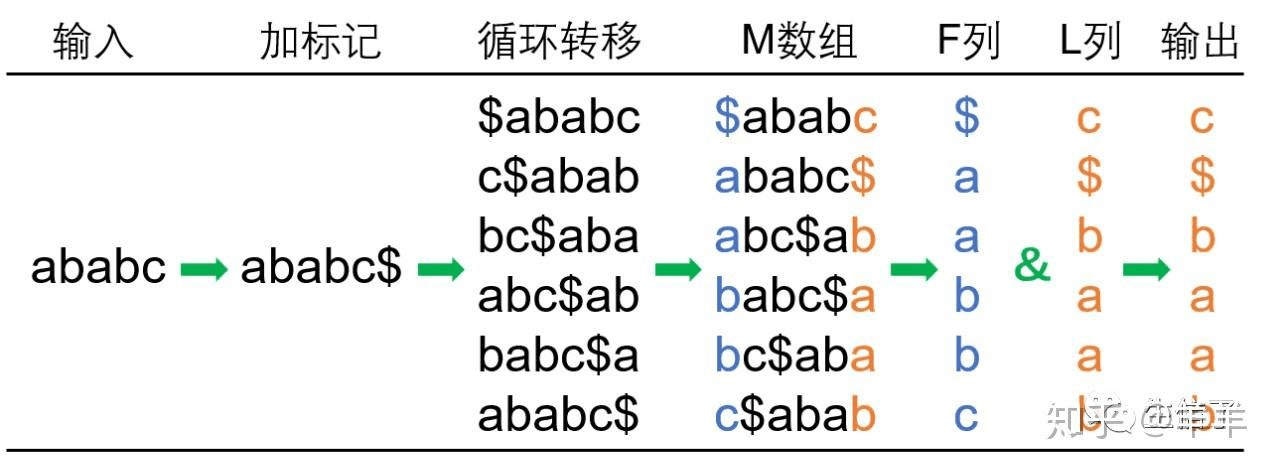
如下图,编码过程如下,最终保存 L 列即可:
解码
解码过程,直接看参考资料一吧,这里不写了。总之知道最终可以从 L 列恢复出原字符串。
场景
压缩
为什么可以压缩,参考资料二给了很好的例子。原来字符串中频繁出现某个词,比如 'the',则就会有很多的 't' 由于 'hexxxxxxxxt' 的排序聚在一块:
s = 'the_small_or_the_big_or_the_large_or_the_huge_man'
l = 'neeeelegerrrmml_hhhgghiurtttt_bl_as_a___oooa____$h'
这样重复的部分就可以压缩了。
子字符串查找
这里还要用到 FM-Index 方法,但是这里就不细讲了(其实我也没怎么看)。反正知道结合这种方法,可以快速查找子字符串。
他的好处就是构建完这个 BWT 编码之后,可以快速查找字符串了,多次查找比较适合这种场景。不想 KMP 这种每次都要重复比对。即:
BWT + FM-index 适合“对同一个超长文本做海量查询”,而 KMP / BM 适合“一次性匹配、无需建索引”的场景。
但其实 后缀数组 也可以做到。两个比较是:后缀数组更快,但是内存消耗更大。一般而言,在这个时代下,时间比空间更重要。(来自 2026 年的呐喊:但是内存涨价好多啊)
BWT + FM-Index 典型用途:DNA / RNA 测序,比如测得一个小片段,去匹配人类基因组哪个位置。当然也有用后缀数组做的。