01.大模型的基本原理
复制本地路径 | 在线编辑
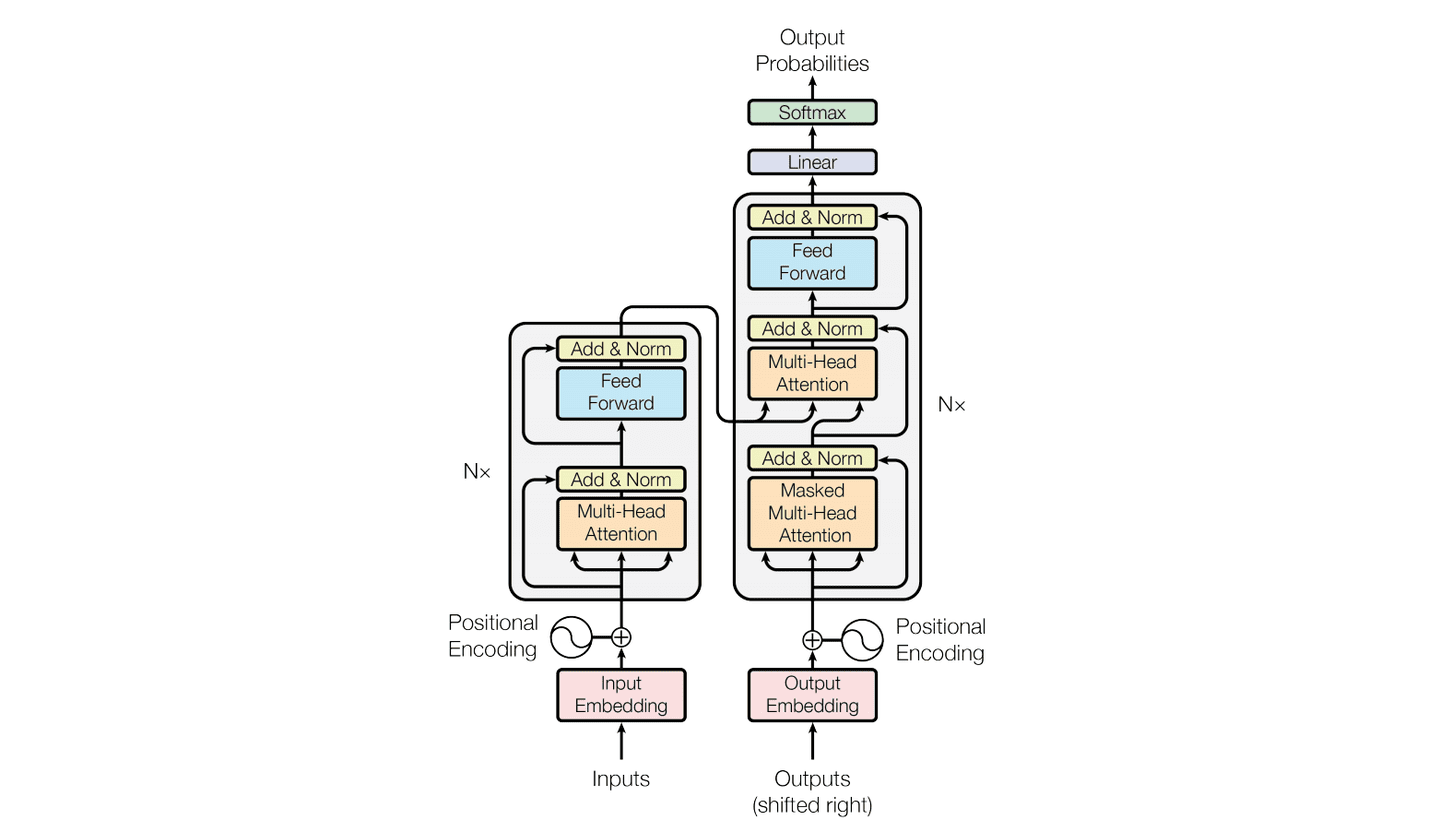
下面通过问答的方式来整理大模型的基本原理。首先 Transformer 经典图先放这里。
问题一
大模型是基于 Transformer 的,那他的输入是什么?Transformer 有两个输入啊,一个是 Encoder 的输入,一个是 Decoder 的输入。
一句话:现在大家口中的大模型(GPT、LLaMA、ChatGLM 这类),只用了 Transformer 的 Decoder,没有 Encoder!
详细说明
现在自回归大语言模型(GPT 系列、LLaMA、Qwen、Llama 等):
直接砍掉了 Encoder,只用 Decoder 堆叠,叫 Decoder-only 架构
它的输入只有一个:
你给的 Prompt / 上文文本
流程:
- 把你输入的一句话/一段话,分词 → 词嵌入 + 位置编码
- 送入多层 Decoder(带因果掩码)
- 逐字预测下一个 token,自回归生成
👉 全程没有 Encoder,不需要第二个输入,就只剩一路输入。
问题二
那既然这样,他是怎么预测第一个词的?平白无故生成第一个词?
既然是 Decoder-only 架构,那就相当于把用户的问题作为 Decoder 的输入呗,此时会预测出第一个词,这个阶段叫 Prefill。
然后把新产生的词作为输入,继续预测下一个词,这个阶段叫 Decode,也叫自回归阶段。
比如用户问:How are you,此时把 How are you 作为 Decoder 的输入,会预测出第一个词 Fine,然后把这个 Fine 作为输入,即此时输入是 How are you. Fine,继续预测下一个词 Thank,以此类推,直到预测出最后一个词。