Sampling
背景介绍
了解 LLM 的基本原理都知道,大模型每次会输出的是词典中各个词的概率,然后我们根据概率分布从字典中选取一个最合适的词。
Sampling 就是这一步骤,也就是调整输出的概率、以及如何根据概率选词。
首先要知道一个名词:logits,这个就是指的大模型输出的词典各个词的概率。
调整概率
没错,很多时候,我们不是直接用大模型生成的概率,而是在其基础上再调整一下。
温度 (Temperature)
温度 (Temperature) 操作用于调整 logits 的概率分布整体情况,能让概率分布变得尖锐或者平坦。利用了吉布斯分布的特点,其实很简单,就是 softmax 那里多除以一个 T 而已。
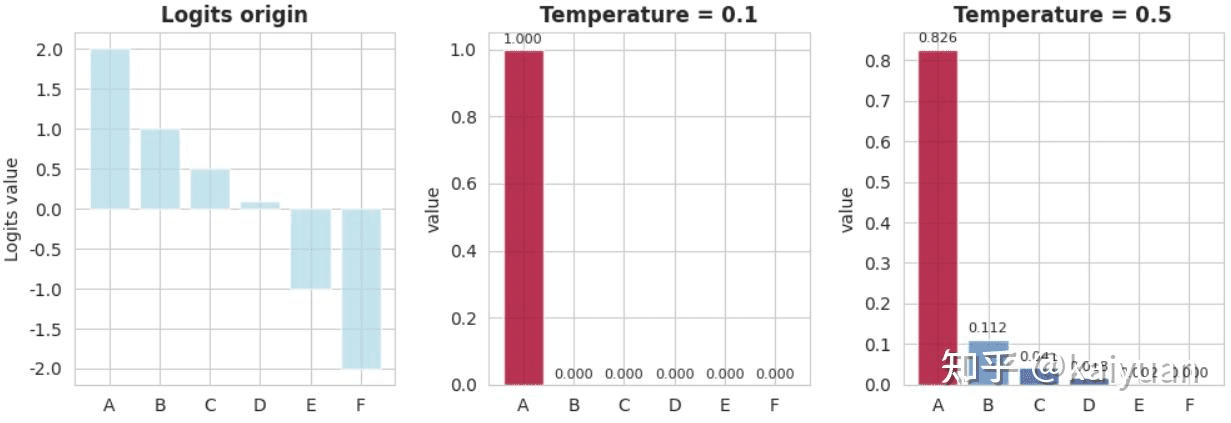
改变 T 值的大小,能够影响输出的概率:
- 0 < T < 1,称之为低温。logits 概率数组将会变得锐化,值与值之间的差距拉大。
- T > 1,称之为高温。logits 概率数组变得更加平缓,值与值之间的差距缩小。
TopK、TopP、MinP
目前一个 LLM 字典大小能到 151K,随机采样时范围并不需要这么大,为了降低随机的范围,可去掉一些低概率值。常见的方式是用过滤来缩小范围。
- TopK:概率排序后,保留概率最大的 K 个值。
- TopP:概率排序后,取累积概率到 P 的值,先排序,然后算累加值,直到累加值大于 P 为止。
- MinP:保留所有概率至少为最高概率的 P 倍的候选词。
若字典是 ['A', 'B', 'C', 'D', 'E', 'F'],logits 为 [0.6, 0.3, 0.05, 0.03, 0.015, 0.005]
- 用 TopK = 4,则 logits 变为:
[0.6, 0.3, 0.05, 0.03, 0, 0]; - 用 TopP = 0.95,则 logits 变为:
[0.6, 0.3, 0.05, 0, 0, 0]; - 用 MinP = 0.5,则 logits 变为:
[0.6, 0.3, 0, 0, 0, 0];
通过示例,了解这几个处理方式的问题:
- TopK 会选取到一些概率低的样本。例:logits 为
[0.6, 0.3, 0.05, 0.03, 0.015, 0.005],TopK = 3,0.05 概率被采样进去了。 - TopP 有采集的数量过多的问题。例:logits 为
[0.2, 0.2, 0.2, 0.2, 0.1, 0.1],TopP = 0.95,全部值都有效。 - MinP 有采样过少的问题。例:logits 为
[0.8, 0.1, 0.05, 0.03, 0.015, 0.005],MinP = 0.5 时,仅保留了一个值。
所以通常的 LLM 推理过程中,会混合使用这些策略。
惩罚 (Penalty)
惩罚(Penalty)是根据历史的输出字符情况增加一些超参来调整局部的 logits 值,是一个局部缩放操作。
为什么需要惩罚这种机制?一个理想 LLM 像人类一样输出合适的结果,但目前的 LLM 还不能完全达到人类的水平。在输出采样实践中,如果纯靠概率模型可能会犯一些错误,比如:循环、重复、冗余。

惩罚作为对 logits 的一种处理手段,抑制一些基本的错误。常见的惩罚手段有:
- 频率惩罚(frequency penalty):对出现过的词,根据其出现频率降低 logits 值,频率越高衰减越严重。
- 存在惩罚(presence penalty):对出现过的词,在 logits 中减去一个相应惩罚值,每个词至多惩罚一次。
- 重复惩罚(repetition penalty):对重复出现的词进行衰减,类似频率处理。
操作顺序
除了温度、惩罚外,还有其它能修改 logits 数值的方式,比如:
- 偏置(bias):给指定的词添加一个偏置项,计算方式:
logits[i] += bias[i]; - 掩膜(mask):将掩膜外的值置为 0;
根据概率选择词
这里可能会奇怪,每一步取最大的概率不就可以了。的确有这个方法,这是贪婪搜索(greedy search),但贪婪搜索保证的是单步最优,没有考虑多步之间的联系,不能保证累积概率最大。
举个例子,如下图所示,采用贪婪采样,在 step 1 选择 "吃"(概率 0.6),step 2 选择 "你"。两步的累积概率为 0.6 * 0.3 = 0.18;与之对比,若 step 1 选 "爱"、step 2 选 "吃",最后能够得到累积概率 0.3 * 0.7 = 0.21,数值比贪婪算法的结果更大。
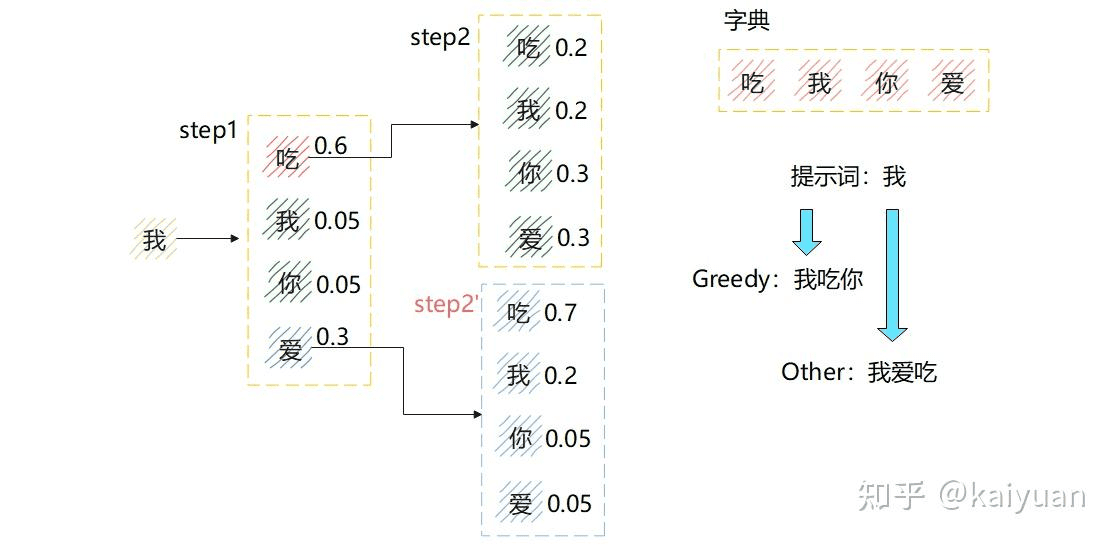
从上面图也能看出,这是一个多叉树求最优解问题。的确有最优解,问题是树实在是太大了,根本无法穷举。
束搜索 (Beam Search)
beam search 是一种结合 topK 和剪枝的搜索算法,每次保留束宽(beam width)k 个结果。beam search 的基本步骤:
- 对首次输出进行 topK 排序,选取前 k 个值;
- 根据上一轮的 k 个值,分别获得 k 个输出,每个分支进行 topK 排序,计算累积概率;
- 对全局 k * k 个累积概率排序,选取前 k 个值;
- 重复步骤 2、3,直到 k 个分支遇到结束符,最后以累积概率最大的分支作为结果。
上面的步骤可以一扫而过即可,总之意会即可,用的时候再查。