并行优化二:CP
CP(Context Parallelism):其实就是 SP 序列并行的细节实现。
SP - 序列并行
先把 SP 的说明拿到这里来:
单条序列太长,导致中间激活值太大,单张 GPU 放不下。所以可以切分序列,放在不同显卡中。如果大白话理解,就是原来训练的时候用到 hello, world,现在切成 hello 和 world 分别放在不同显卡中。
为什么切序列不会有问题
第一次看这个感觉很奇怪,序列居然可以切分到不同设备。但其实,对于线性层而言,序列中各个单词是独立的,因为线性层就是每个向量自己乘上一个矩阵而已。
序列中的单词唯一需要通信的地方是计算 K/V,其实这个时候进行通信即可。此时 K/V 要在 GPU 之间交换,最简单的做法就还是各自广播(AllGather 通信),当然还有一些流水线通信做法,比如分为好几轮,第一轮是 0->1, 1->2, 2->0,第二轮是 0->2, 1->0, 2->1,这样可以流水线并行。
除了这个,最后要计算 softmax,即 softmax(QK^T),这个时候上面的流水线就不一定能有作用。不过也有对应的方法,叫 online softmax,不是先算完整 \(QK^T\) 再 softmax,而是一边收到 K/V 块,一边增量更新 softmax。这个就比较细节了,不谈了。
总之,序列并行中,通信只需要在计算 K/V 的时候进行即可。
CP - 细节说明
所以 CP 就是讲的上面所说的:Attention 计算的时候要通信,具体怎么通信。就是在解释上面说的流水线并行是啥意思而已。
第一步:各自计算:如下所示,每个 GPU 自己有 Q/K/V,然后能计算出一个输出。
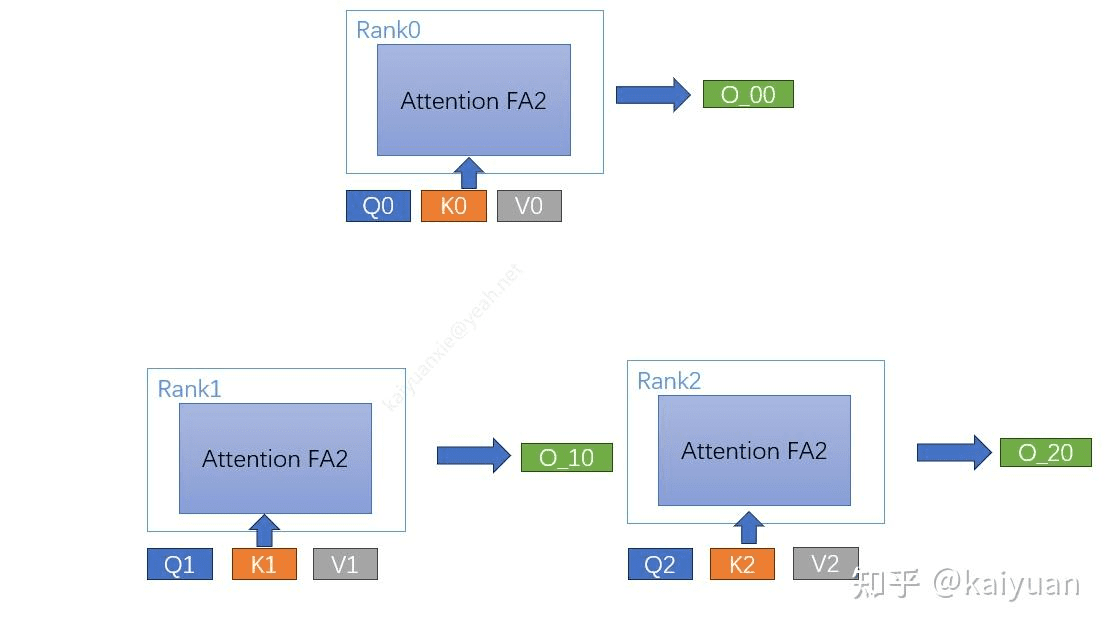
第二步:通信:就像上面章节说的,流水线并行,多轮进行两两通信。比如第一轮之间 0->1, 1->2, 2->0,得到之后,去计算新的输出。
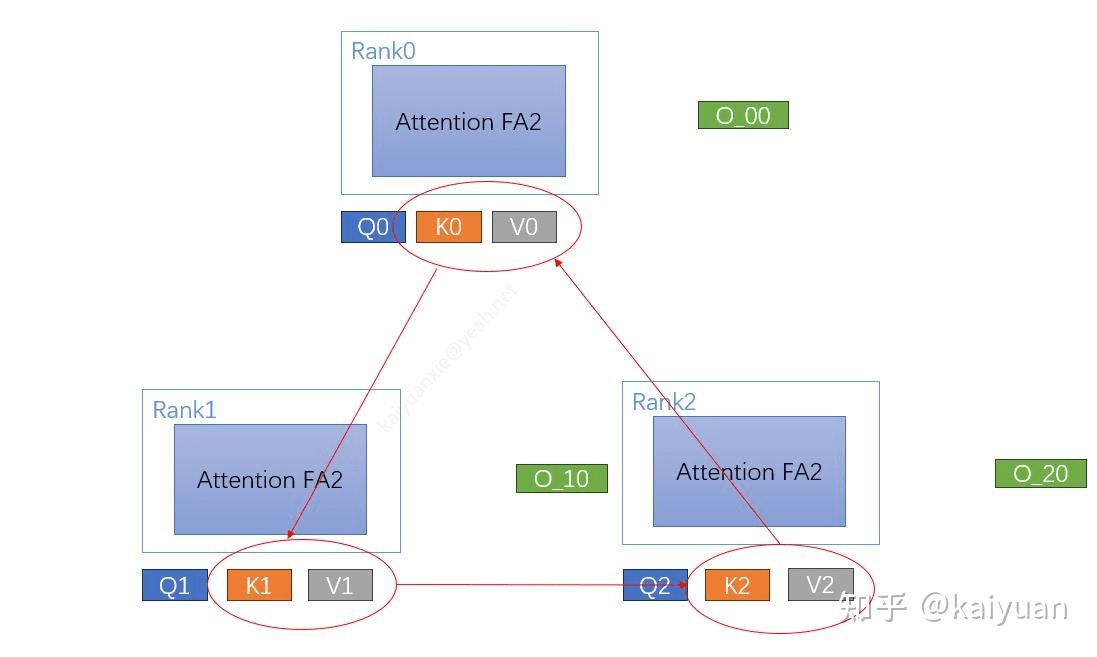
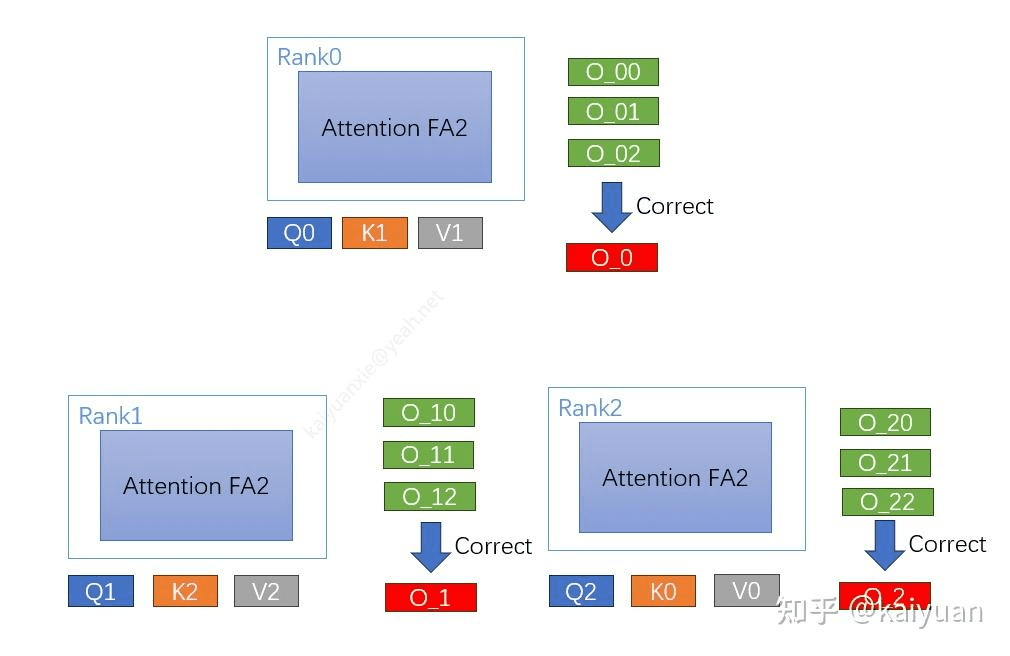
第三步:修正和输出:几轮交换之后,每个 GPU 都得到了分批次的输出,要进行修正(具体细节看下面),最后得到输出。
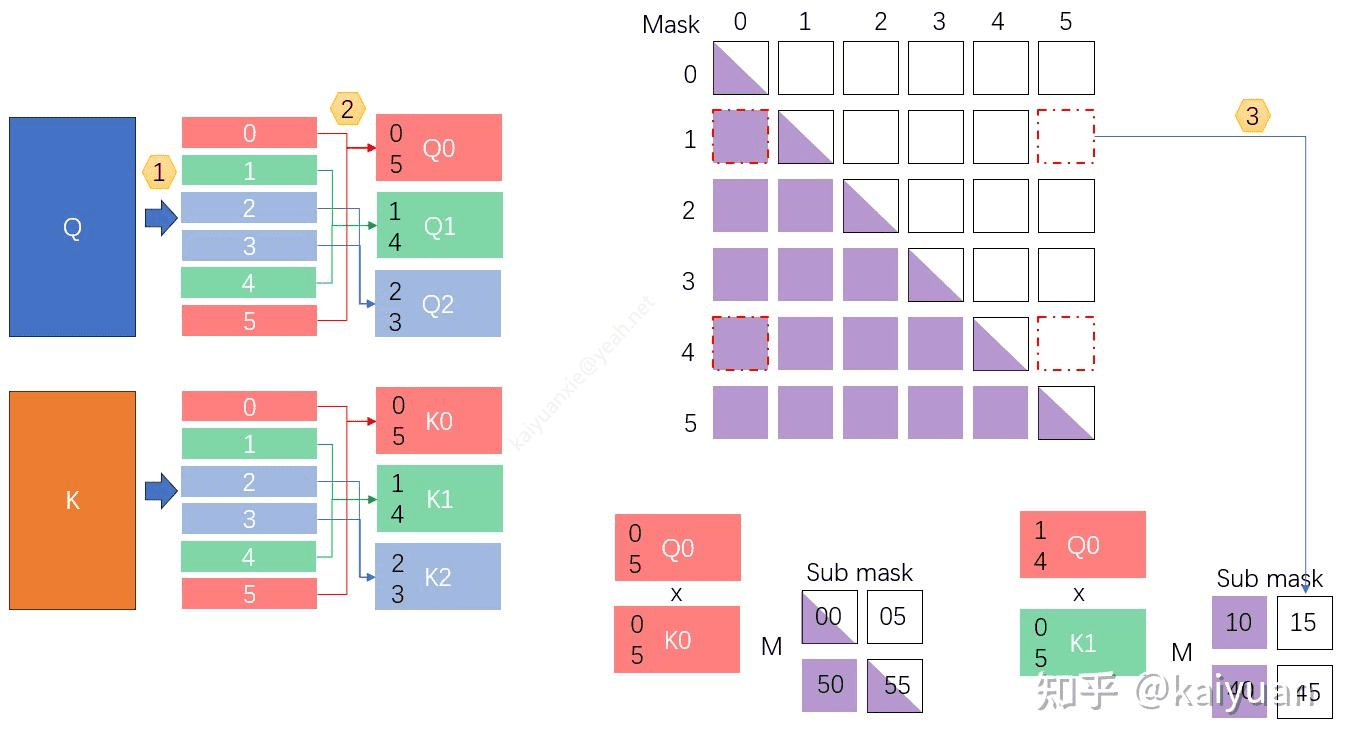
Causal Mask
正常的 Transformer 中要用到因果掩码,即每个 token 只能看到自己及之前的 token。所以这里切分之后,也要保证这样的情况。比如下图,按照三等分为例。
-
将 Q 和 K 沿 sequence 维度等分成
3×2份,这样 Q 和 K 都有 6 份,序号 [0, 1, 2, 3, 4, 5]; -
然后对称取数据组合。比如 Q0 拿到数据块 [0, 5]、Q1 拿到数据 [1, 4],K 也是同样的处理,子块的数据大小依然为
seq/cp_size。 -
由于要与计算数据映射,mask 需要切成
3×2 × 3×2的形状,当不同子块 Q 与不同的子块 K 进行计算后要掩膜操作时,拿取的 mask 块是根据 idx 进行寻找,比如 Q0 与 K1 的 sub mask,需要的子块 mask:01、51、04、54。mask 子块的 idx 是 Q 与 K 的数据 idx 两两组合得到。
当然这里还有很多的细节,很繁琐,具体看文章开头给的参考链接。
修正输出
这里是要知道 Flash Attention 的原理,核心是需要知道:计算 softmax 时会用到 max 操作,反正知道是要用到某个最大值就行。
所以如果分块的话,数据交换前几轮用到的 max 很可能是错的,要修正,这里就不谈了,太细节了,用到的时候自行搜索。

总结
所以 CP 没什么好说的,就是 SP 在 Attention 计算时的细节实现。这里写得很泛,只是了解初步的原理。