为什么该程序写入比读取慢?
复制本地路径 | 在线编辑
感谢作者:https://www.bilibili.com/video/BV1gu41117bW
非常好的视频,很有意思的问题。
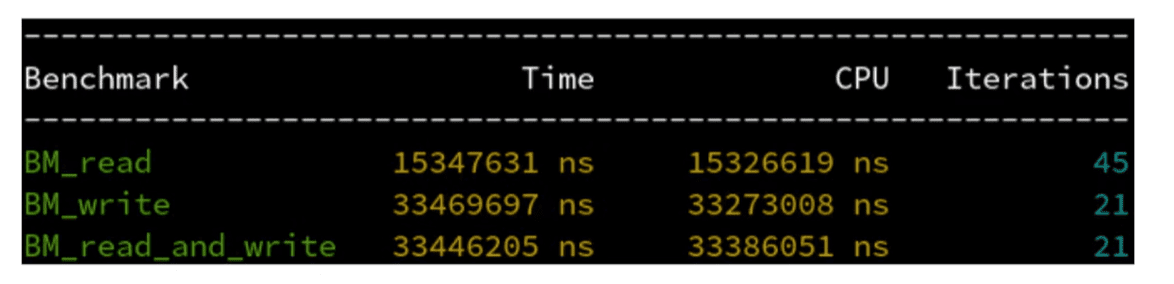
如下图所示,为什么写入数组比读取数组要慢?
问题说明
void BM_read(benchmark::State &bm) {
for (auto _ : bm) {
float ret = 0.0f;
#pragma omp parallel for reduction(+:ret)
for (size_t i = 0; i < n; i++) {
ret += a[i];
}
benchmark::DoNotOptimize(ret);
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_read);
void BM_write(benchmark::State &bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i++) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_write);
void BM_read_and_write(benchmark::State &bm) {
for (auto _ : bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i++) {
a[i] = a[i] + 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_read_and_write);
回答
这是 Cache 和 Memory 打交道的原因。如果 Cache 向 Memory 中写入数据,必须是 64B 为寻址。上面的代码中给某个地址每次写入和读取的是 4B 数据时,所以写入时:
- CPU 向 Cache 发送 4B 数据(读取时正好反过来,最后 Cache 向 CPU 返回 4B 数据)
- Cache 从 Memory 读取对齐后的地址,读取 64B 数据到 Cache (读取时也会有)
- Cache 把其中对应的 4B 数据替换掉,择机写回 Memory(也就是说不是立即写回,假如下一次又要修改这个 64B 部分或整体数据,就可以利用 Cache 存好的了)(读取时没有)
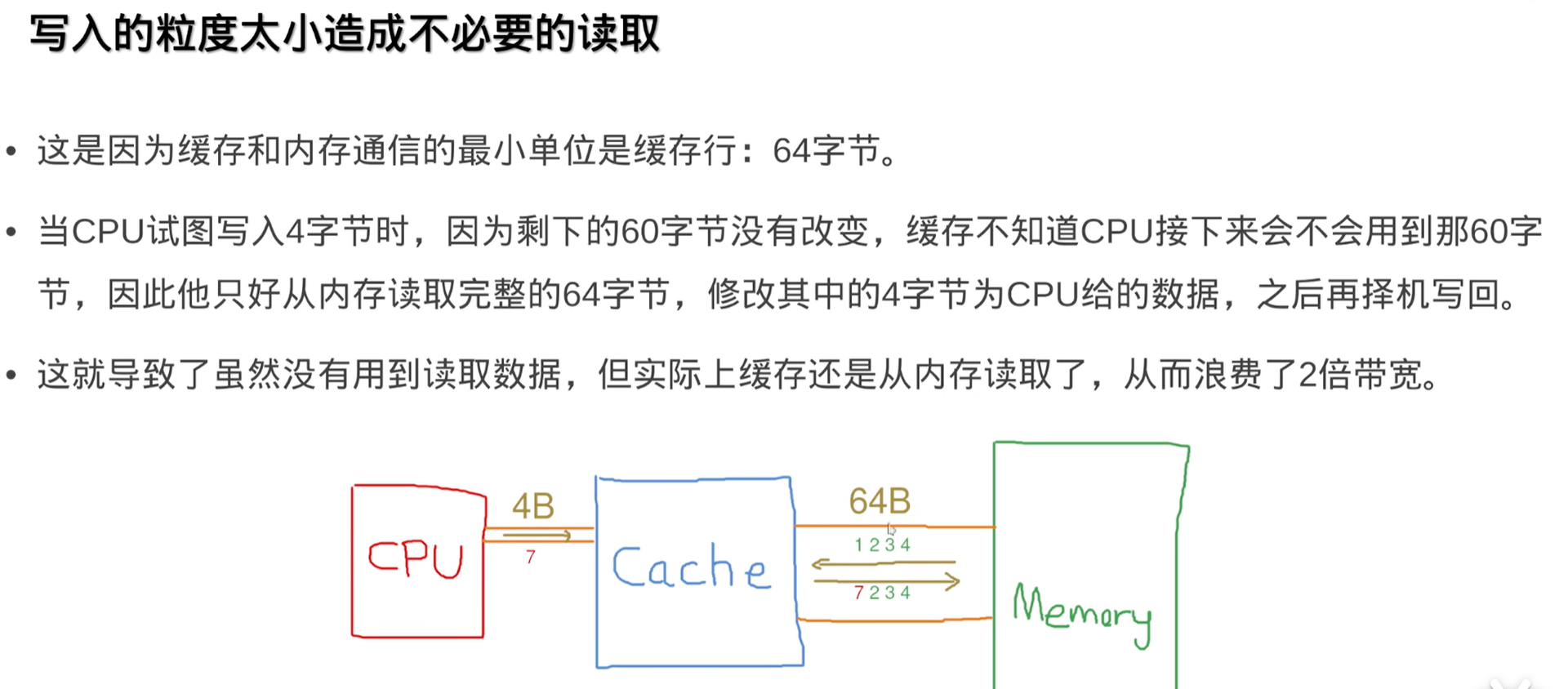
而读取就没有这个问题,Cache 也是从 Memory 读取 64B,但是由于上面代码读取数组时顺序读取,当某次 Cache 从 Memory 搬运 64B 之后,读取下一个数据时这个 64B 已经存在 Cache 里面了,所以 Cache 直接就返回结果了。
综上,假设数组有 64*n B,那么读取时 Cache 从 Memory 读取 n 次;写入时 Cache 必须从 Memory 读取 n 次(关键),向 Memory 写回也是 n 次,所以结果就写入比读取慢两倍。