马尔可夫模型
主要参考 https://datawhalechina.github.io/easy-rl/#/chapter2/chapter2
引用请引用上述链接,本文大部分内容和语句来源于此,只是简单加了一些自己的理解,自己理解有可能不对,请批判参考!
引言
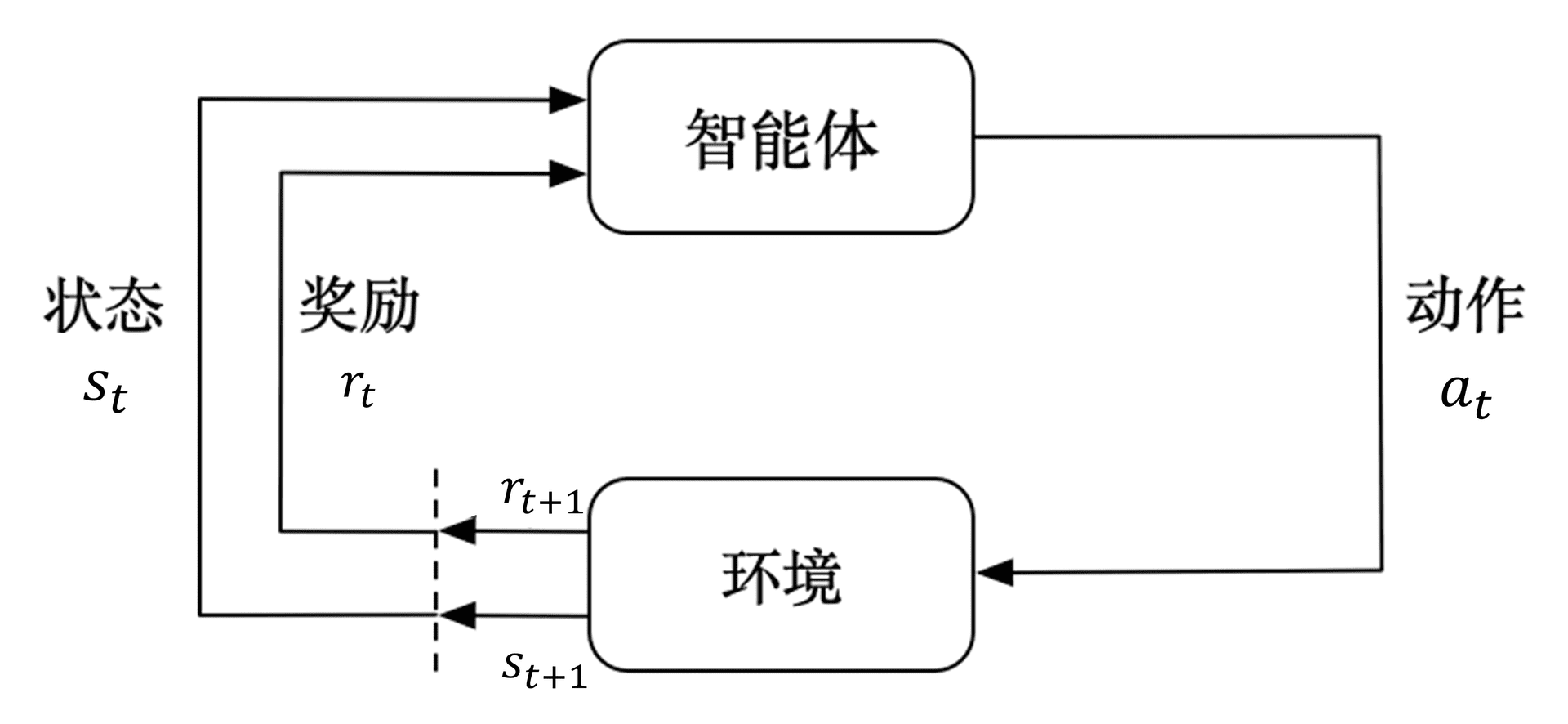
下图介绍了强化学习里面智能体与环境之间的交互,智能体得到环境的状态后,它会采取动作,并把这个采取的动作返还给环境。环境得到智能体的动作后,它会进入下一个状态,把下一个状态传给智能体。在强化学习中,智能体与环境就是这样进行交互的,这个交互过程可以通过马尔可夫决策过程来表示,所以马尔可夫决策过程是强化学习的基本框架。
本章将介绍马尔可夫决策过程。在介绍马尔可夫决策过程之前,我们先介绍它的简化版本:马尔可夫过程(Markov process,MP)以及马尔可夫奖励过程(Markov reward process,MRP)。通过与这两种过程的比较,我们可以更容易理解马尔可夫决策过程。其次,我们会介绍马尔可夫决策过程中的策略评估(policy evaluation),就是当给定决策后,我们怎么去计算它的价值函数。最后,我们会介绍马尔可夫决策过程的控制,具体有策略迭代(policy iteration) 和价值迭代(value iteration)两种算法。在马尔可夫决策过程中,它的环境是全部可观测的。但是很多时候环境里面有些量是不可观测的,但是这个部分观测的问题也可以转换成马尔可夫决策过程的问题。
1.1 马尔可夫过程
1.1.1 马尔可夫性质
马尔可夫性质
在随机过程中,马尔可夫性质(Markov property)是指:一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。
以离散随机过程为例,假设随机变量 \(X_0,X_1,\cdots,X_T\)构成一个随机过程。这些随机变量的所有可能取值的集合被称为状态空间(state space)。如果 \(X_{t+1}\) 对于过去状态的条件概率分布仅是 \(X_t\) 的一个函数,则
其中,\(X_{0:t}\) 表示变量集合 \(X_{0}, X_{1}, \cdots, X_{t}\),\(x_{0: t}\) 为在状态空间中的状态序列 \(x_{0}, x_{1}, \cdots, x_{t}\)。马尔可夫性质也可以描述为给定当前状态时,将来的状态与过去状态是条件独立的。如果某一个过程满足马尔可夫性质,那么未来的转移与过去的是独立的,它只取决于现在。马尔可夫性质是所有马尔可夫过程的基础。
1.1.2 马尔可夫链
马尔可夫过程是一组具有马尔可夫性质的随机变量序列 \(s_1,\cdots,s_t\),其中下一个时刻的状态\(s_{t+1}\)只取决于当前状态 \(s_t\)。我们设状态的历史为 \(h_{t}=\left\{s_{1}, s_{2}, s_{3}, \ldots, s_{t}\right\}\)(\(h_t\) 包含了之前的所有状态),则马尔可夫过程满足条件:
从当前 \(s_t\) 转移到 \(s_{t+1}\),它是直接就等于它之前所有的状态转移到 \(s_{t+1}\)。
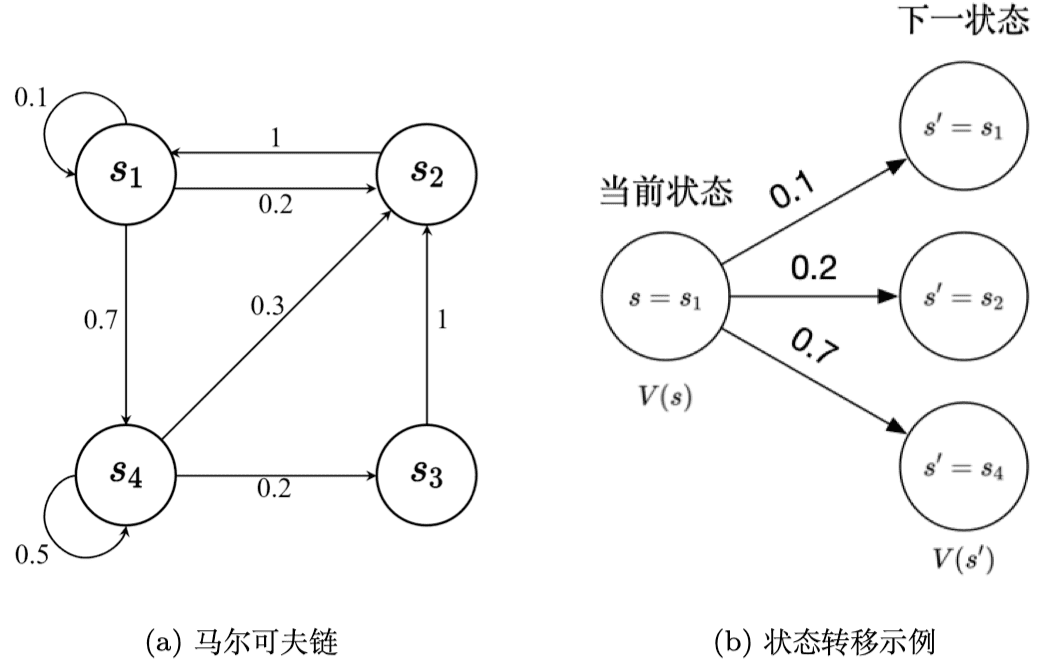
离散时间的马尔可夫过程也称为马尔可夫链(Markov chain)。马尔可夫链是最简单的马尔可夫过程,其状态是有限的。例如,图 2.2 里面有4个状态,这4个状态在 \(s_1,s_2,s_3,s_4\) 之间互相转移。比如从 \(s_1\) 开始,\(s_1\) 有 0.1 的概率继续存留在 \(s_1\) 状态,有 0.2 的概率转移到 \(s_2\),有 0.7 的概率转移到 \(s_4\) 。如果 \(s_4\) 是我们的当前状态,它有 0.3 的概率转移到 \(s_2\),有 0.2 的概率转移到 \(s_3\),有 0.5 的概率留在当前状态。
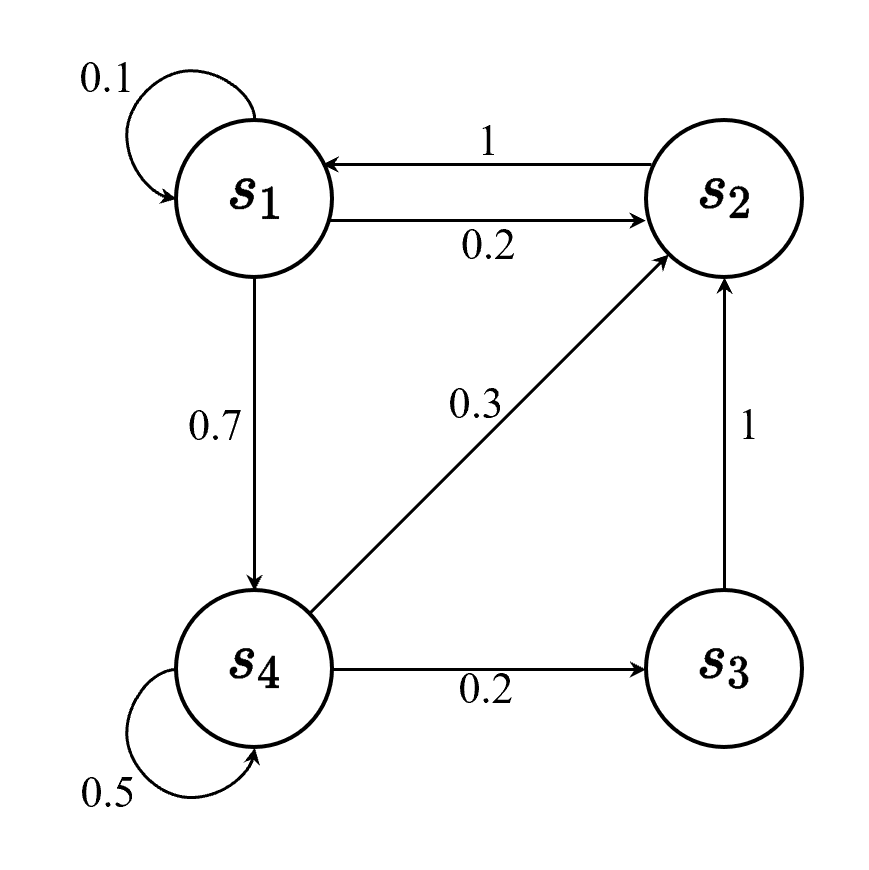
我们可以用状态转移矩阵(state transition matrix)\(\boldsymbol{P}\) 来描述状态转移 \(p\left(s_{t+1}=s^{\prime} \mid s_{t}=s\right)\):
状态转移矩阵类似于条件概率(conditional probability),它表示当我们知道当前我们在状态 \(s_t\) 时,到达下面所有状态的概率。所以它的每一行描述的是从一个节点到达所有其他节点的概率。
1.1.3 马尔可夫过程的例子
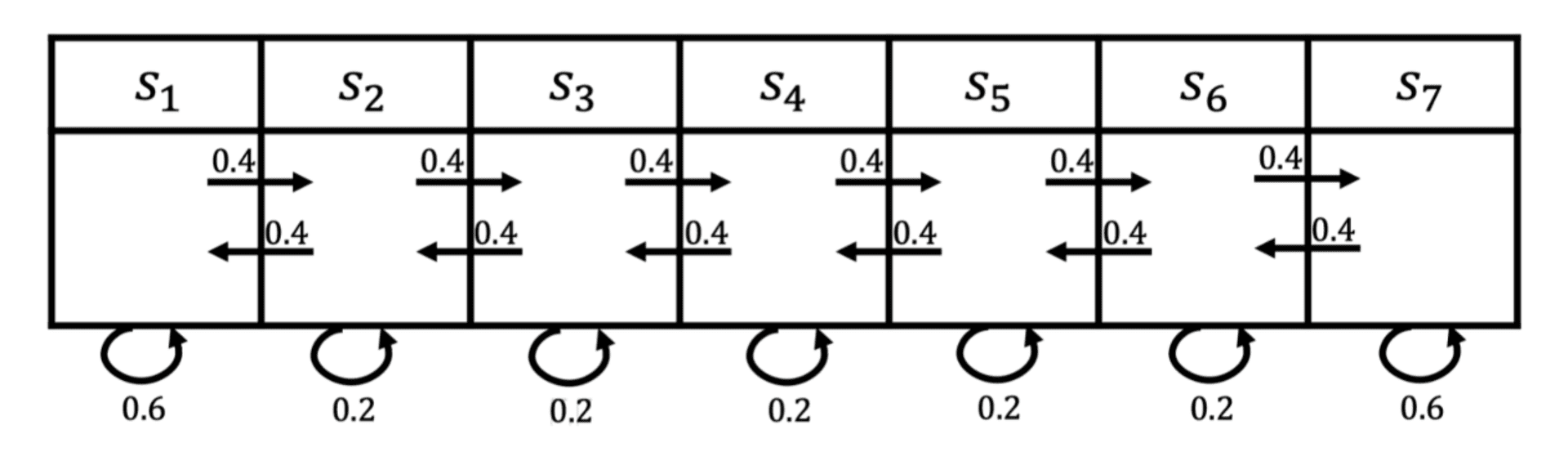
下图所示为一个马尔可夫过程的例子,这里有七个状态。比如从 \(s_1\) 开始,它有0.4的概率到 \(s_2\) ,有 0.6 的概率留在当前的状态。 \(s_2\) 有 0.4 的概率到\(s_1\),有 0.4 的概率到 \(s_3\) ,另外有 0.2 的概率留在当前状态。所以给定状态转移的马尔可夫链后,我们可以对这个链进行采样,这样就会得到一串轨迹。例如,假设我们从状态 \(s_3\) 开始,可以得到3个轨迹:
- \(s_3, s_4, s_5, s_6, s_6\);
- \(s_3, s_2, s_3, s_2, s_1\);
- \(s_3, s_4, s_4, s_5, s_5\)。
通过对状态的采样,我们可以生成很多这样的轨迹。
1.2 马尔可夫奖励过程
1.2.1 回报与价值函数
回报(return)是奖励的逐步叠加,假设时刻\(t\)后的奖励序列为\(r_{t+1},r_{t+2},r_{t+3},\cdots\),则回报为
其中,\(T\)是最终时刻,\(\gamma\) 是折扣因子,越往后得到的奖励,折扣越多。这说明我们更希望得到现有的奖励,对未来的奖励要打折扣。
当我们有了回报之后,就可以定义状态的价值了,就是状态价值函数(state-value function)。对于马尔可夫奖励过程,状态价值函数被定义成回报的期望,即
我们使用折扣因子的原因如下。第一,有些马尔可夫过程是带环的,它并不会终结,我们想避免无穷的奖励。第二,我们并不能建立完美的模拟环境的模型,我们对未来的评估不一定是准确的,我们不一定完全信任模型,因为这种不确定性,所以我们对未来的评估增加一个折扣。我们想把这个不确定性表示出来,希望尽可能快地得到奖励,而不是在未来某一个点得到奖励。第三,如果奖励是有实际价值的,我们可能更希望立刻就得到奖励,而不是后面再得到奖励(现在的钱比以后的钱更有价值)。最后,我们也更想得到即时奖励。有些时候可以把折扣因子设为 0(\(\gamma=0\)),我们就只关注当前的奖励。我们也可以把折扣因子设为 1(\(\gamma=1\)),对未来的奖励并没有打折扣,未来获得的奖励与当前获得的奖励是一样的。折扣因子可以作为强化学习智能体的一个超参数(hyperparameter)来进行调整,通过调整折扣因子,我们可以得到不同动作的智能体。
在马尔可夫奖励过程里面,我们如何计算价值呢?如图 2.4 所示,马尔可夫奖励过程依旧是状态转移,其奖励函数可以定义为:智能体进入第一个状态 \(s_1\) 的时候会得到 5 的奖励,进入第七个状态 \(s_7\) 的时候会得到 10 的奖励,进入其他状态都没有奖励。我们可以用向量来表示奖励函数,即
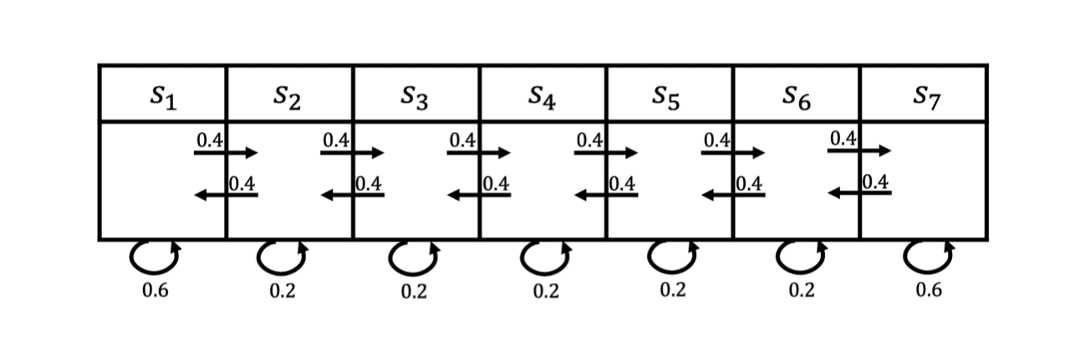
下面举几个状态组合的例子,(\(\gamma=0.5\))来采样回报 \(G\)。
-
\(s_{4}, s_{5}, s_{6}, s_{7}\) 的回报: \(0+0.5\times 0+0.25 \times 0+ 0.125\times 10=1.25\)
-
\(s_{4}, s_{3}, s_{2}, s_{1}\) 的回报: \(0+0.5 \times 0+0.25\times 0+0.125 \times 5=0.625\)
-
\(s_{4}, s_{5}, s_{6}, s_{6}\) 的回报: \(0+0.5\times 0 +0.25 \times 0+0.125 \times 0=0\)
这里就引出了一个问题:
当我们有了一些轨迹的实际回报时,怎么计算它的价值函数呢?
比如我们想知道 \(s_4\) 的价值,即当我们进入 \(s_4\) 后,它的价值到底如何?一个可行的做法就是我们可以生成很多轨迹,然后把轨迹都叠加起来。比如我们可以从 \(s_4\) 开始,采样生成很多轨迹,把这些轨迹的回报都计算出来,然后将其取平均值作为我们进入 \(s_4\) 的价值。这其实是一种计算价值函数的办法,也就是通过蒙特卡洛(Monte Carlo,MC)采样的方法计算 \(s_4\) 的价值。
1.2.2 贝尔曼方程
但是这里我们采取了另外一种计算方法,从价值函数里面推导出贝尔曼方程(Bellman equation):
其中,
- \(s'\) 可以看成未来的所有状态,
- \(p(s'|s)\) 是指从当前状态转移到未来状态的概率。
- \(V(s')\) 代表的是未来某一个状态的价值。我们从当前状态开始,有一定的概率去到未来的所有状态,所以我们要把 \(p\left(s^{\prime} \mid s\right)\) 写上去。我们得到了未来状态后,乘一个 \(\gamma\),这样就可以把未来的奖励打折扣。
- \(\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} \mid s\right) V\left(s^{\prime}\right)\) 可以看成未来奖励的折扣总和(discounted sum of future reward)。
贝尔曼方程定义了当前状态与未来状态之间的关系。未来奖励的折扣总和加上即时奖励,就组成了贝尔曼方程。
贝尔曼方程的推导过程
1.2.3 贝尔曼方程解释
贝尔曼方程定义了状态之间的迭代关系,即
假设有一个马尔可夫链如图 2.5a 所示,贝尔曼方程描述的就是当前状态到未来状态的一个转移。如图 2.5b 所示,假设我们当前在 \(s_1\), 那么它只可能去到3个未来的状态:有 0.1 的概率留在它当前位置,有 0.2 的概率去到 \(s_2\) 状态,有 0.7 的概率去到 \(s_4\) 状态。所以我们把状态转移概率乘它未来的状态的价值,再加上它的即时奖励(immediate reward),就会得到它当前状态的价值。贝尔曼方程定义的就是当前状态与未来状态的迭代关系。
我们可以把贝尔曼方程写成矩阵的形式:
当我们把贝尔曼方程写成矩阵形式后,可以直接求解:
我们可以直接得到解析解(analytic solution):
我们可以通过矩阵求逆把 \(\boldsymbol{V}\) 的价值直接求出来。但是一个问题是这个矩阵求逆的过程的复杂度是 \(O(N^3)\)。所以当状态非常多的时候,比如从10个状态到1000个状态,或者到100万个状态,当我们有100万个状态的时候,状态转移矩阵就会是一个100万乘100万的矩阵,对这样一个大矩阵求逆是非常困难的。所以这种通过解析解去求解的方法只适用于很小量的马尔可夫奖励过程。
1.3 马尔可夫决策过程
相对于马尔可夫奖励过程,马尔可夫决策过程多了决策(决策是指动作),其他的定义与马尔可夫奖励过程的是类似的。
此外,状态转移也多了一个条件,变成了\(p\left(s_{t+1}=s^{\prime} \mid s_{t}=s,a_{t}=a\right)\)。未来的状态不仅依赖于当前的状态,也依赖于在当前状态智能体采取的动作。马尔可夫决策过程满足条件:
个人注解:这里的动作,按照上面的例子,就是向左走、向右走;之前是统计价值函数时,向左走和向右走都考虑;现在则是我向左走的时候,价值函数是多少。
对于奖励函数,它也多了一个当前的动作,变成了 \(R\left(s_{t}, a_{t}\right)\)。当前的状态以及采取的动作会决定智能体在当前可能得到的奖励多少。
1.3.1 马尔可夫决策过程中的策略
策略定义了在某一个状态应该采取什么样的动作。知道当前状态后,我们可以把当前状态代入策略函数来得到一个概率,即
概率代表在所有可能的动作里面怎样采取行动,比如可能有 0.7 的概率往左走,有 0.3 的概率往右走,这是一个概率的表示。
已知马尔可夫决策过程和策略 \(\pi\),我们可以把马尔可夫决策过程转换成马尔可夫奖励过程。在马尔可夫决策过程里面,状态转移函数 \(P(s'|s,a)\) 基于它当前的状态以及它当前的动作。因为我们现在已知策略函数,也就是已知在每一个状态下,可能采取的动作的概率,所以我们就可以直接把动作进行加和,去掉 \(a\),这样我们就可以得到对于马尔可夫奖励过程的转移,这里就没有动作,即
对于奖励函数,我们也可以把动作去掉,这样就会得到类似于马尔可夫奖励过程的奖励函数,即
1.3.2 和马尔可夫奖励过程的区别
马尔可夫决策过程里面的状态转移与马尔可夫奖励过程以及马尔可夫过程的状态转移的差异如图 2.9 所示。马尔可夫过程/马尔可夫奖励过程的状态转移是直接决定的。比如当前状态是 \(s\),那么直接通过转移概率决定下一个状态是什么。
但对于马尔可夫决策过程,它的中间多了一层动作 \(a\) ,即智能体在当前状态的时候,首先要决定采取某一种动作,这样我们会到达某一个黑色的节点。到达这个黑色的节点后,因为有一定的不确定性,所以当智能体当前状态以及智能体当前采取的动作决定过后,智能体进入未来的状态其实也是一个概率分布。
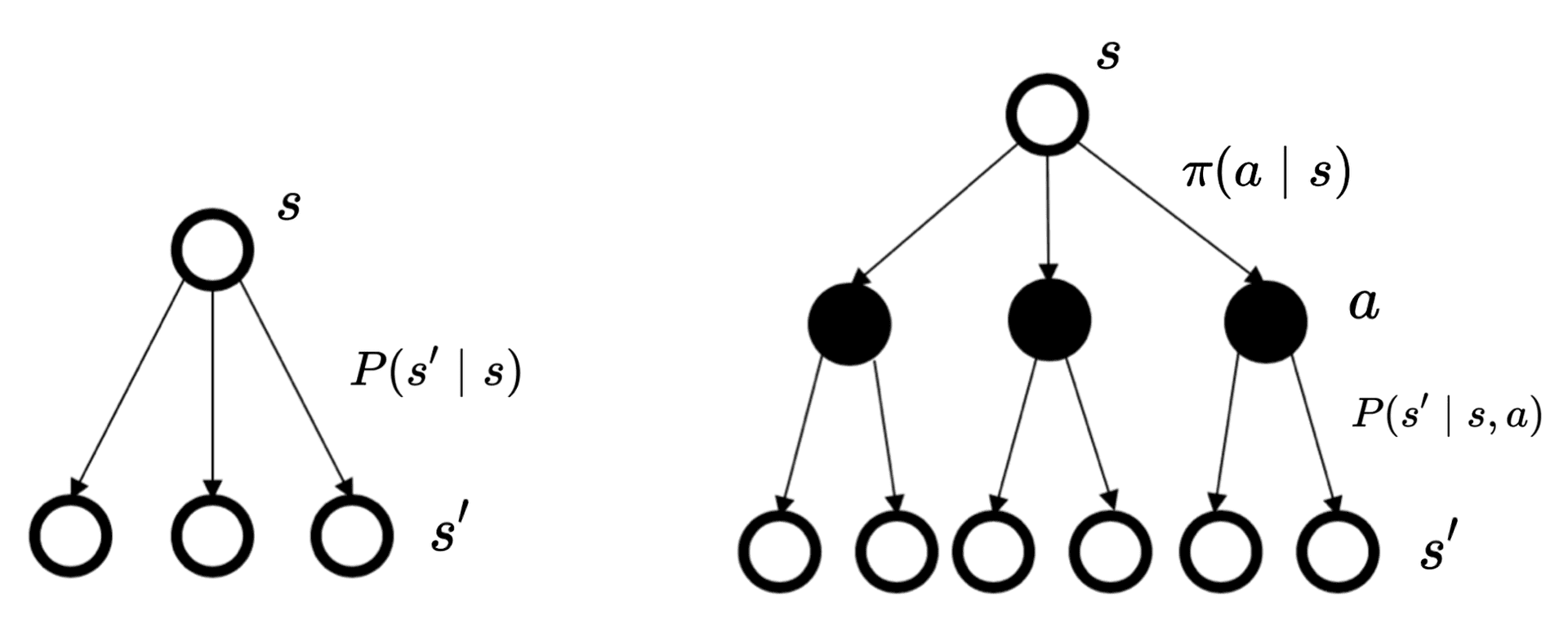
个人注解:这个图后面还会看到。其实还是很好理解的,如果一开始理解不了可以继续看。
1.3.3 马尔可夫决策过程中的价值函数
之前我们介绍的马尔可夫过程中的价值函数可定义为
其中,\(G_t\) 是回报,定义为
现在有了决策这一过程,为了体现决策/动作的重要性,引入一个 Q 函数(Q-function)。Q 函数也被称为动作价值函数(action-value function)。Q 函数定义的是在某一个状态采取某一个动作,它有可能得到的回报的一个期望,即
很容易能理解到:
个人注解:理解 \(\pi(a \mid s)\) 的含义。现阶段可以理解成他就是一种规定。比如掷色子,现在正面朝上为 3,也就是状态 3;此时选择为状态 4 的概率是 ⅙,这就是一种先天规定。当然后面会看到,很多时候这个值也需要算出来,但现在就先这样理解。
对 Q 函数的贝尔曼方程进行推导:
1.3.4 贝尔曼期望方程
通过对状态价值函数进行分解,我们就可以得到一个类似于之前马尔可夫奖励过程的贝尔曼方程————贝尔曼期望方程(Bellman expectation equation):
对于 Q 函数,我们也可以做类似的分解,得到 Q 函数的贝尔曼期望方程:
贝尔曼期望方程定义了当前状态与未来状态之间的关联。
我们进一步进行简单的分解,首先有:
我们把式(2.9)代入式(2.8)可得
这个式子代表当前状态的价值与未来状态价值之间的关联。
我们把式(2.8)代入式(2.9)可得
这个式子代表当前时刻的 Q 函数与未来时刻的 Q 函数之间的关联。
上面两个式子是贝尔曼期望方程的另一种形式,后续在强化学习的各种方法中,这个方程很重要。
\(\pi(a \mid s)\) 和 \(p(s' \mid s,a)\) 的区别是什么?
我们按照加法为例子,现在可以加一减一,当前数字为 n 时称作状态 n。
\(\pi\) 表示状态 \(s\) 的时候取动作 \(a\) 的概率。比如状态 2 的时候,加一的概率是 0.5,减一的概率是 0.5。
\(p\) 表示状态 \(s\) 做了动作 \(a\) 之后成为状态 \(s'\) 的概率。比如状态 2 的时候,我们采取动作加一,那么变成状态 3 的概率是 1,变成状态 4 的概率是 0,当然现实情况往往都是有噪声和随机性,大部分不是这种例子下完全是 1 和 0 的概率。
1.3.5 我们要做什么
强化学习要做什么,目标是价值最大,即得到最佳价值函数(optimal value function),定义为
在这过程中,我们最终确定好每次的策略,从而得到这样的价值函数。在这种最大化情况中,我们得到的策略就是最佳策略,即
如何找这样的策略,最朴实无华的:穷举。包括下围棋,其实确实可以穷举找到神之一手,但显然很多时候没法这样做,这就是强化学习后面要做的:找一个最佳策略去使得价值最大。