PD: Prefill and Decode
复制本地路径 | 在线编辑
大模型首先把用户的问题作为输入,预测出第一个词,这个阶段叫 Prefill,也叫预填充阶段。
然后把新产生的词加到输入后面,继续预测下一个词,这个阶段叫 Decode,也叫自回归阶段。
比如用户问:How are you,此时把 How are you 作为 Decoder 的输入,会预测出第一个词 Fine,然后把这个 Fine 作为输入,即此时输入是 How are you. Fine,继续预测下一个词 Thank,以此类推,直到预测出最后一个词。
当然上面的说法比较泛化,真正的操作的是 Token,而不是词。
- Prefill 相当于要计算所有的 Token,这个是计算密集型阶段
- Decoder 每次新来一个 Token,然后计算,这个是串行阶段
那岂不是prefill很少会用到,只是用户第一次提问的时候会有?
本质上可以这样说,但本质是有新的内容输入,比如:
-
上下文刷新 / 压缩:当对话长度接近模型上下文窗口上限,系统会自动压缩、截断、重排历史上下文,生成新的完整上下文序列,哪怕你没发新话,也会触发一次全量 Prefill。
-
工具 / 函数调用(Agent 核心场景):AI 调用工具后,工具返回的结果是完整已知的批量 token,必须走一次 Prefill,模型才能读懂结果并继续生成回答,这个过程用户没有任何新输入。
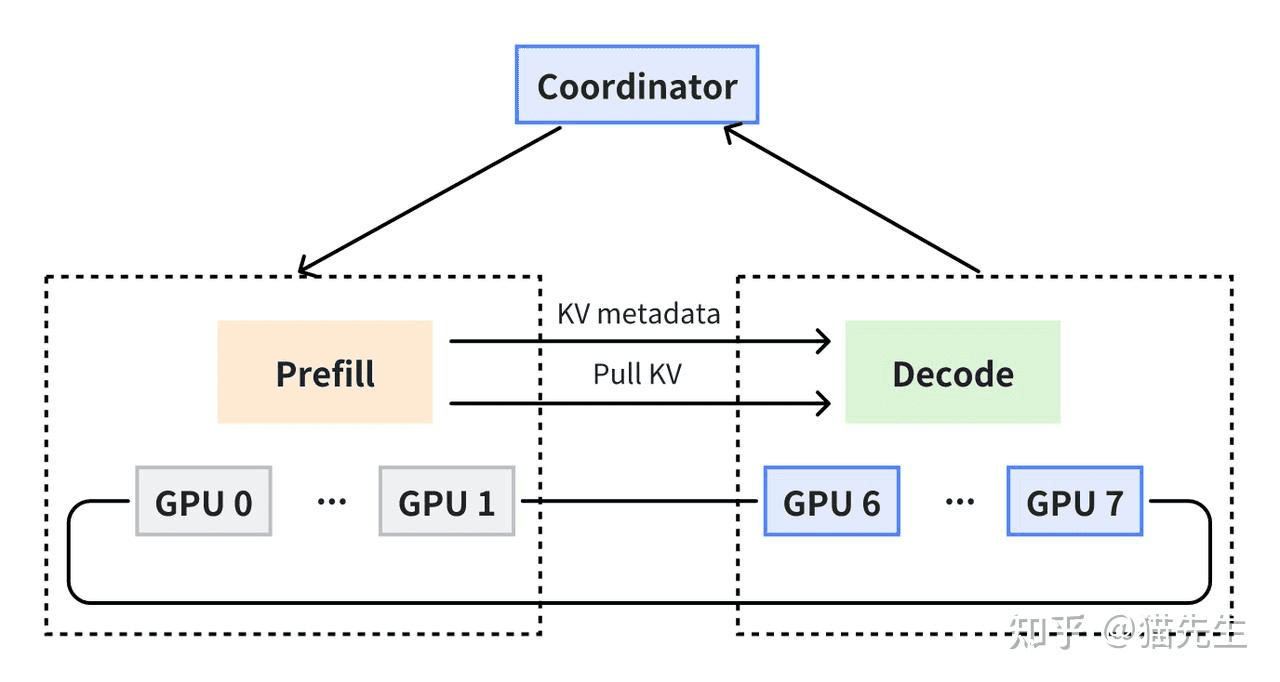
在传统集成式推理流水线中,LLM的Prefill和Decode阶段往往被置于同一GPU上运行,导致资源需求不匹配,资源利用率不高。因为很明显,两个阶段计算量是不一样的。
所以现在通常是将Prefill实例和Decode实例分开部署,这个牵扯到很多很多的内容.... 是 AI Infra 里面非常重要和庞大的子领域了,这里不讲。对于我来说,只要知道有这个东西就行。