结语
强化学习就暂时学到这里,再往下就是太过细节了,和我的初衷不符。我是对强化学习能够自反馈这一特点比较感兴趣,于是打算看看的。
综合下来,看起来我们还是要定义每一步的瞬时价值 \(r\),其中包括结束时候的价值。为什么这样说,分为两类方法:
基于价值方法
第一类方法是基于价值的方法,动态规划、蒙特卡洛、时序差分,比如 Q-Learning,他计算价值的时候本身就是要知道 \(r\):
基于策略方法
第二类方法是基于策略的方法,乍一看公式里面好像和价值没有关系,但是他是每次收集完数据后对参数进行更新,在这个采样过程中要计算 \(G(\tau)\),即每个轨迹的价值,这个时候还是会要每一步的瞬时价值 \(r\):
其中,\(\tau\) 表示产生的一个轨迹 (trajectory),其由一系列的状态和动作组成,表示为 \({s_0, a_0, s_1, a_1, ..., s_T, a_T}\)。而 \(G(\tau)\) 就是这个轨迹的总回报(total return),即:
这里我就直接按照第五章大部分拷贝过来了。
具体内容
我们的目标是最终训练出 \(\pi_\theta\),为了形式化这个目标,我们定义目标函数
其中,\(\tau\) 表示产生的一个轨迹 (trajectory),其由一系列的状态和动作组成,表示为 \({s_0, a_0, s_1, a_1, ..., s_T, a_T}\)。而 \(G(\tau)\) 就是这个轨迹的总回报(total return),即:
这里 \(r_t\) 表示在时刻 t 的奖励。
很自然的,我们对 \(J(\theta)\) 进行求梯度,经过推导,可以得到:
证明过程
以下内容来自:https://datawhalechina.github.io/easy-rl/#/chapter4/chapter4
对符号进行了替换。
因为我们要让奖励越大越好,所以可以使用**梯度上升(gradient ascent)**来最大化期望奖励。要进行梯度上升,我们先要计算期望奖励 $J(\theta)$ 的梯度。我们对 $J(\theta)$ 做梯度运算
$$
\nabla J(\theta)=\sum_{\tau} G(\tau) \nabla p_{\theta}(\tau)
$$
其中,只有 $p_{\theta}(\tau)$ 与 $\theta$ 有关。
奖励函数$G(\tau)$ 不需要是可微分的(differentiable),这不影响我们解决接下来的问题。例如,如果在生成对抗网络(generative adversarial network,GAN)里面,$G(\tau)$ 是一个判别器(discriminator),它就算无法微分,我们还是可以做接下来的运算。
我们可以对 $\nabla p_{\theta}(\tau)$ 使用式 (4.1),得到 $\nabla p_{\theta}(\tau)=p_{\theta}(\tau) \nabla \log p_{\theta}(\tau)$。
$$
\nabla f(x)=f(x)\nabla \log f(x) \tag{4.1}
$$
接下来,我们可得
$$
\frac{\nabla p_{\theta}(\tau)}{p_{\theta}(\tau)}= \nabla \log p_{\theta}(\tau)
$$
注:上式用了对数函数的求导公式,对数函数 $f(x)=\log x$ 的导数为 $\frac{1}{x}$。
如式 (4.2) 所示,我们对 $\tau$ 进行求和,把 $G(\tau)$ 和 $\log p_{\theta}(\tau)$ 这两项使用 $p_{\theta}(\tau)$ 进行加权,既然使用 $p_{\theta}(\tau)$ 进行加权,它们就可以被写成期望的形式。也就是我们从 $p_{\theta}(\tau)$ 这个分布里面采样 $\tau$ ,去计算 $G(\tau)$ 乘 $\nabla\log p_{\theta}(\tau)$,对所有可能的 $\tau$ 进行求和,就是期望的值(expected value)。
$$
\begin{aligned}
\nabla J_{\theta}&=\sum_{\tau} G(\tau) \nabla p_{\theta}(\tau)\\&=\sum_{\tau} G(\tau) p_{\theta}(\tau) \frac{\nabla p_{\theta}(\tau)}{p_{\theta}(\tau)} \\&=
\sum_{\tau} G(\tau) p_{\theta}(\tau) \nabla \log p_{\theta}(\tau) \\
&=\mathbb{E}_{\tau \sim p_{\theta}(\tau)}\left[G(\tau) \nabla \log p_{\theta}(\tau)\right]
\end{aligned} \tag{4.2}
$$
我们用蒙特卡洛的思想,大量采样,然后进行训练。采样 \(N\) 个 \(\tau\),计算每一个的值,把每一个的值加起来,就可以得到梯度,即
第二项 log 的推导过程
$$
\begin{aligned}
\nabla \log p_{\theta}(\tau) &= \nabla \left(\log p(s_1)+\sum_{t=1}^{T}\log p_{\theta}(a_t|s_t)+ \sum_{t=1}^{T}\log p(s_{t+1}|s_t,a_t) \right) \\
&= \nabla \log p(s_1)+ \nabla \sum_{t=1}^{T}\log p_{\theta}(a_t|s_t)+ \nabla \sum_{t=1}^{T}\log p(s_{t+1}|s_t,a_t) \\
&=\nabla \sum_{t=1}^{T}\log p_{\theta}(a_t|s_t)\\
&=\sum_{t=1}^{T} \nabla\log p_{\theta}(a_t|s_t)
\end{aligned}
$$
注意, $p(s_1)$ 和 $p(s_{t+1}|s_t,a_t)$ 来自环境,$p_\theta(a_t|s_t)$ 来自智能体。$p(s_1)$ 和 $p(s_{t+1}|s_t,a_t)$ 由环境决定,与 $\theta$ 无关,因此 $\nabla \log p(s_1)=0$ ,$\nabla \sum_{t=1}^{T}\log p(s_{t+1}|s_t,a_t)=0$。
> 说实话上面这段话没太懂,我对 p 的理解可能还是不到位,但是我感觉不用钻牛角尖。当时在这上面花的时间有点多。
顺理成章的,训练 \(\theta\) 的方式就是:
具体的方式,首先固定好参数 \(\theta\),然后去交互,交互完以后,就可以得到大量游戏的数据。记录好每个状态 s 采取了动作 a,多次尝试。根据采集的数据更新模型,然后继续采样,反反复复。
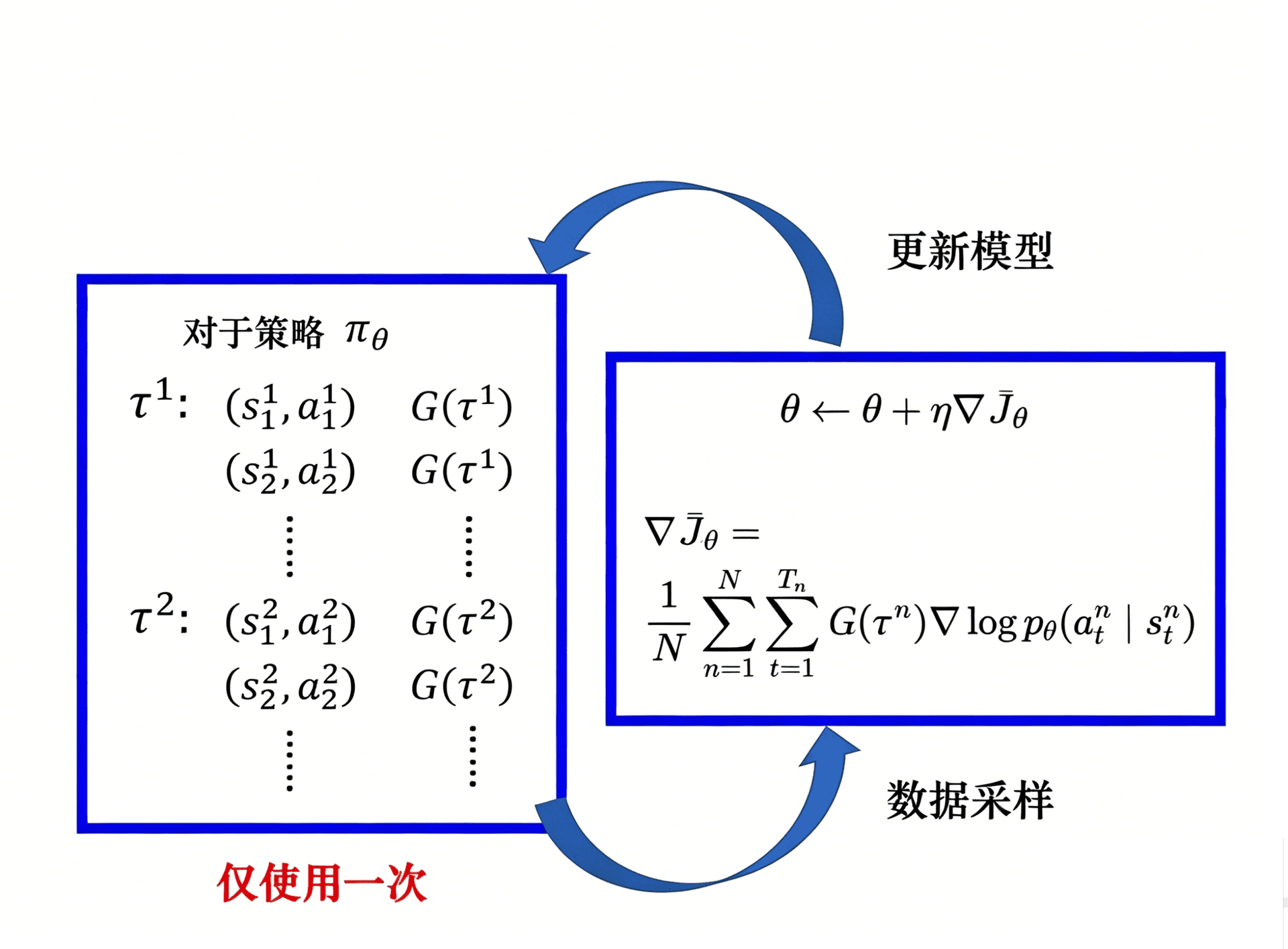
注意,采样的数据只会用一次。我们采样这些数据,然后用这些数据更新参数,再丢掉这些数据。接着重新采样数据,才能去更新参数。
而且其实从公式中也可以看出,本质上就是每对训练数据,乘上一个 $G(\tau)$ 进行加权,然后就和平常的分类问题一样了,可以直接套用 PyTorch 之类的框架就可以了。