MHA 和 MQA 和 GQA
复制本地路径 | 在线编辑
前提知识
Standard Attention
传统的 Attention 如下,就是 QKV 的矩阵乘法,其中 \(Q = W_Q X\),其他类似。
\[
Attention(Q, k, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
\]
MHA
本质上是把原来的 Attention 计算拆分成多个小份的 Attention 计算,然后并行计算,最后再合回原来的维度。
$$
\begin{aligned}
head_i = Attention(Q_i, K_i, V_i) \
H = concat(head_1, head_2, ..., head_h) \
MHA(Q, K, V) = H W^O
\end{aligned}
$$
之所以这样,是希望能够理解输入不同部分之间的关系。因此切分成不同的头,每个头独立学习不同关系,比如第一个头学习的是主语和宾语之间的关系,第二个头学习的是谓语和宾语之间的关系,以此类推。
MQA
MQA 是为了节省显存用的,其本质就是计算各个 \(head_i\) 的时候,共享同样的一份 K 和 V 矩阵,只让 Q 保留了原始多头的性质。
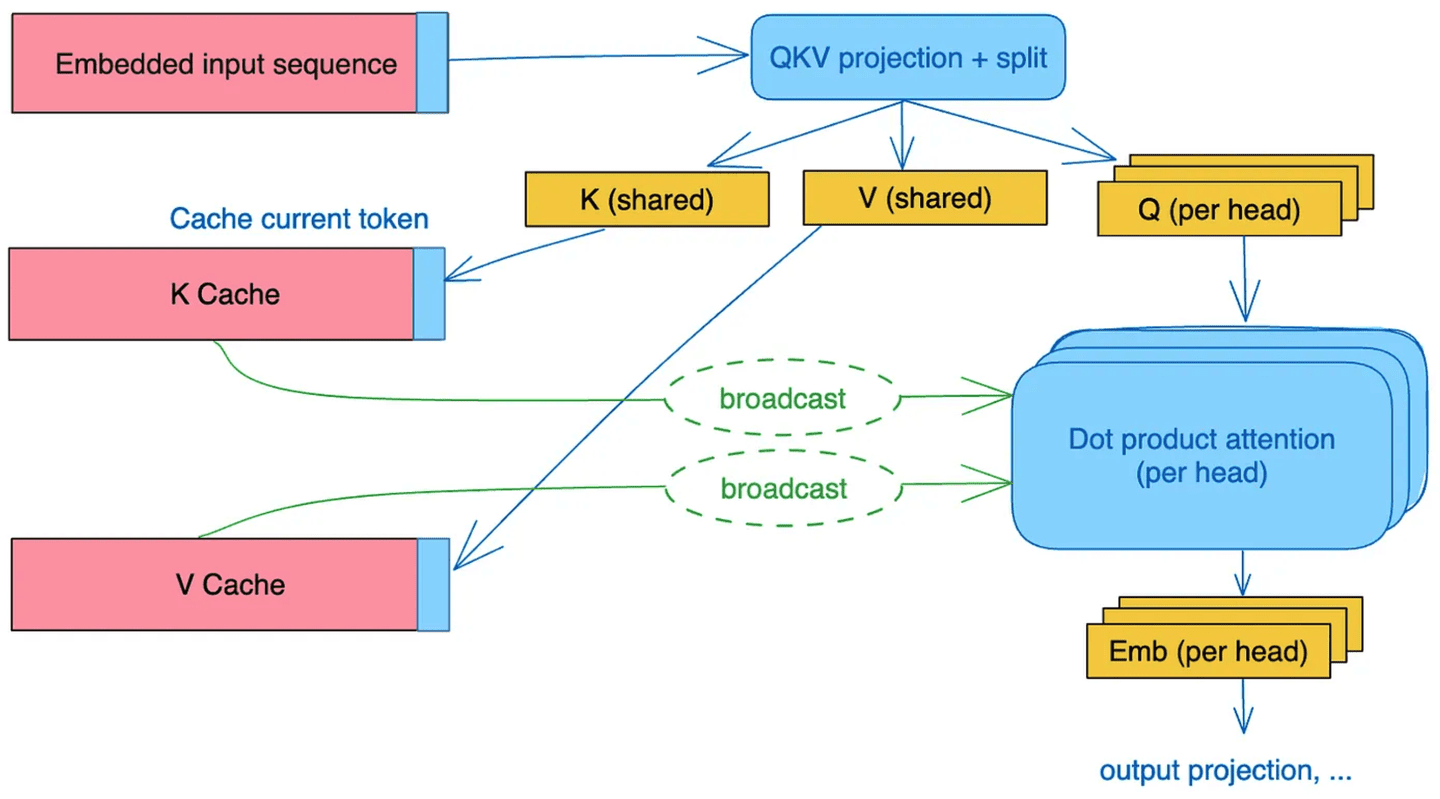
原来是 \(K = W^K X\),然后拆分成 \(K_1, K_2, ...\);现在这里的 \(W_K\) 维度变小了,相当于最后算出的 \(K\) 就和原来的 \(K_1\) 一样大小,\(V\) 也是同理。
关键点就是 \(W_K\) 的维度变小,显存占用也变小了。
GQA
GQA 其实就是 MQA 的扩展,MQA 太粗暴了,直接共享一套。那 GQA 就是共享 n 套呗,没啥可说的。