Record 文件内容整合
📄 judge.txt
主动探测
1. 成本: 需要遍布全球的节点来执行测量
2. 可伸缩性有挑战: 随着范围扩大, 成本和时间都会增长比较多
3. 测量工具本身的局限性: 不是所有的 IP 会响应 ICMP 包
4. 时延不能完全反映地理距离: 有误差, 路由的传播和地理不对应
5. 精度比较一般, 精度和预测范围的 Tradeoff(待考虑)
选取什么样的探针有很大的运气成分.
近似地标
- 依赖地表的分布
- 使用地标的相对距离: 很扯
需要 traceroute 的探测: traceroute 本身会得到错误的结果
信息挖掘
1. 范围: 只能测量一小部分的地址
2. 得到的信息不稳定
3. 得到的地址难以纠错
探针
1. 数量少, 分布集中, 网络类型集中 (GeoCAM)
域名
1. CDN/服务器 造成的误差可能会很大
2. Unstable: dynamic IP addresses of those local web services would also lower their effectiveness.
3. 精度大部分只有城市而不是经纬度
物联网
1. 得到的结果很少很少, GeoCAM-16K
2. 纠错: CDN/服务器, 用户自己上传错误
用户主动上传
1. 只有特定的信息方才能完成(社交网络, 搜索引擎)
反向 DNS
1. Incorrect hints: Reverse DNS hostname entries are managed by the ISP themselves, or sometimes their clients, and can become outdated.
2. Name ambiguity: RDNS hostname 中的地理暗示通常比较短, 因此会匹配很多城市, 现在的技术很难对其进行有效筛选(时延或者距离). (TODO: 我想知道城市名称是不是存在地理聚集的特征?)
3. IP Coverage: 33.4% of IPv4 addresses have hostnames, 14.1% of these hostnames could contain exact city matches and only 23.5% of them could contain airport code matches.
- DRoP
1. DRoP places 99% of IPs in 6 test domains within 10 km of their actual location. 但是它评测的 ISP 都是比较规则命名的 ISP, 所以评估有夸大的嫌疑.
2. 专注 Router 定位
1. 需要主动定位, 时间上可能会有些慢
2. 主动定位的时延约束比较低
3. 正则表达式比较简陋, 容易错过一些关键词
4. 进行推断比较勉强, 所以误差很大
In 2017, Scheitle et al. also compared locations extracted by DRoP against CBG-feasible boundaries and reported that most DRoP-inferred locations were incorrect
- HLOC
和 DRoP 差不多, 下面是一些其他的
1. 一些阈值设置的有问题: 比如考虑的城市人口阈值, 城市范围等
- MSrDNS
1. 分类的标准有待商榷
2. 本质上为大量的 Ground-Truth 来堆出来的结果
- CoNEXT
1. 时延约束比较低, 导致最后的城市选择可能会有问题
2. 学习的方式有待商榷
2016 Query-Geo
📄 record.txt
00. Shortest-Ping && Geoping
Shortest-Ping 很暴力,就是用观测点去探测目标主机,谁的延迟短,那么就把目标主机位置近似为该观测点位置。
Geoping 其实原理也是一样的,但是它的进步是引入了地标这样的概念,通过 VP 的延迟去计算 哪个地标更近。
10. Posit
这篇文章,我个人认为可以把它归结于 Geopoing 的改进
原来的 Geoping 是使用欧几里得距离,本质上它这个就是把欧式距离换成别的距离...
03. SOI
这个是在 TBG 中提出来解释 CBG 缺点的,单独提出来说一下。
很简单,就是 CBG 还要线性约束,SOI 直接就把时延按照 2/3 光速来换算,结果竟然都差不多,非常打 CBG 的脸。
01. CBG
这篇就是三角定位,他的 Landmark 实际上就是 Moinitor,也就是必须全部是可以主动发报文的。
其中延迟换算成物理距离,它是利用 线性回归 来得出的。
04. TBG
这个也是引用量很多的论文了,它还考虑了拓扑关系。什么意思呢,举个例子: x->u->t。
按照 CBG 就是直接探测 x->t 距离,而 TBG 是通过拓扑,发现要先探测 u,然后探测 t。
实际上它不是先推测 u 再推测 t,而是推测每一跳的距离。
02. GeoBund
CBG 是每个 Landmark 有线性约束,然后这个 Landmark 去测量任何 target 都会用这个线性关系。
这篇文章认为应该每一对 (Landmark, target) 都有一条线性约束,但是这篇文章的方法却很烂,不提了。
05. Octant
简单理解,就是【CBG 的图】变成了【圆环图】,当然还有一些细节。
它也考虑了先测中间路由器,考虑了不同的约束条件,考虑了最后一跳的延迟。
08. Spotter
这篇文章一个鲜明特点:使用高斯分布来时延和距离换算。
它的前提是获取大量的数据,当测得一个时延的时候,需要有一些数据也是这个大小的时延,然后就可以愉快地高斯分布了。
06. GeoWeight
首先就是 Figure 5 那张图,非常直观。每个圆环都有一个概率数,最后看看哪个区域叠加的概率最多。
之前得到了一个时延,都是固定一个物理距离,或者一段物理距离区间。GeoWeight 认为这段区间中不同物理距离分布概率不同。
对于一个时延,怎么算各个物理区间的概率,这个看 Table 2,最好给个步骤
07. Structon
很好理解的方式,就是通过挖掘网页内容来获得物理地址。
不过还用了一些其他的方法,利用【小型 AS】,利用【BGP routing table】。
08. Checkin-Geo
这也是清华的一篇文章,利用了社交平台中的用户签到。
09. XLBoost-Geo
这篇文章原理也是利用了抽取网页来获取地标这一方法,SLG 和 Structon 也是这种方法,不过都有缺点,一个太少一个太粗糙。
它使用了强化学习从网页中抽取内容,不过我感觉它就是去寻找 Copyright 的格式,用正则就够了
14. Alida
这个杜克大学的一篇文章,算是系统地做了一个定位数据库,可能创新点不够,所以好像没找到它在会议上发过。
11. Drop
这是使用反向 DNS 的首篇文章,方法就是解析路由器的名字。
之前的研究都侧重终端的定位,这篇文章首次提出对路由器进行定位。
然后,它的方法就是分割 DNS hostname,并通过时延来排除模糊选项。它用的数据都是 CAIDA Ark Data 和 CAIDA ITDK Data。
12. Distributed RDNS
这个也是 RDNS,它有两个特点
- 使用机器学习的分类器
- 使用分布式,每个特征的生成是使用不同机器完成的
13. GeoGet
利用 JS 代码,地标选择全部是 WebServer,客户端执行 JS 去访问这些,根据返回时间近似位置。
因为之前的都是使用 ICMP 协议,这个也算比较新鲜,但是缺点很大。只能是 客户端 发起定位。即【客户端去定位自身】。
不过它指明了一点:【延迟和距离没有线性关系】,但是【延迟最小,距离最近】。不太确定这个真的这样吗?
15. SLG
这个本质上其实是提高地标的数量, 然后利用传统方法近似就可以了.
📄 think.txt
1. Posit 那里能不能考虑不同 landmark 有不同的 处理时延
2. Spotter 假定 P(T in H) 是均匀分布,如果用了人口等一些条件处理会怎么样
3. 怎么处理 CDN 这种一个 IP 有多个地点的情况
4. 为什么路由器的定位相对来说那么不准确
5. 为什么移动网络定位不准确
目前需要改进的地方
- 偏远地区的 Landmark
- 路由器等一些基础设施
- 移动网络
- IPv6
6. 一个 IP 可能有多个区域,如何进行评价所得结果的准确性
- CDN, POP, 5G 边缘
- FIT 楼 和 李兆基大楼 可能一个 iP 在两个地方
- 互联网公司常用,为了负载均衡
1. 现在都是筛选可靠的 Landmark, 但是如果反过来, 用主动定位的方式去评价地表的可靠性: DNS, NTP 服务器, 网站域名和网站地
📄 想法.md
Spotter(引入概率的文章)
1. 不同探针的影响力是不一样的,所以不能简单的相加。
2. 每个探针都应该有一个预测
个人想法
- [ ] 评测 IP 地址随着时间变化而有什么变化情况,之前的研究没有把 IP 类型分开啊!国家、AS,最最主要:路由器还是终端。
- [ ] WHOIS 数据库有多少数据是不准确的,包括国家粒度、城市粒度,以及可以研究随着时间的变化。
- [ ] 主动探测中为什么有的距离会判小了?(判大了可以理解,判小了需要仔细研究)
- [ ] 抛去最后一英里,那么时延和地理距离会是什么关系呢?
创新点
- [ ] 利用 Looking Glass 进行分析,而且是不是可以在 Looking Glass 页面上使用提取地理信息的字样,因为这部分网页都很简单
- [ ] 数据集非常的丰富,使用了很多之前的方法,得到的 IP 对应的 AS 分布广泛
如何确保时延尽量精准
- [ ] 只针对路由器吗?因为对终端,由于最后一英里时延的影响,实在太难了。但是如果从路由器再去推测到终端,这个并不是很可行,因为有些路由器,尤其无线路由器,这个覆盖范围可能会很广。
- [ ] 尽量利用同一个 AS 内的探针去进行探测
只对路由器进行定位
1. 要从 ITDK 中抽取出路由器 IP 地址
2. 使用 ZMap 扫描,看一下有多少 IP 是响应 ping、响应 traceroute 的?
3. 相关工作复现
📁 datasource
PlanetLab
PerfSONAR
PingER
RIPE Atlas
BISmark
CAIDA Ark
📄 record.txt
记录各个论文的数据集
- Community-based like PlanetLab
1. Low count
2. Most of them located in Europe and North America
3. Most of them located on academic networks
- Web-based like SLG
1. CDN and 云服务器 导致错误比较多
2. 本地服务器可能是动态 IP 地址, 因此会失效(不过应该都是同一个网段吧??)
1. CBG
A. RIPE hosts
用来作为探测点
B. NLANR AMP
TODO: 用来作为探测点, 但是在官网没找到啊
2. TBG
A. PlanetLab
68 nodes, 用来作为探测点
B. University Dataset
128 hosts at universities across the US, 用来作为目标
C. Abilene Dataset
Abilene Network was a high-performance backbone network created by the Internet2 community in the late 1990s.
In 2007 the Abilene Network was retired and the upgraded network became known as the "Internet2 Network".[1]
这个网络的拓扑应该是公开的(TODO, 存疑, 但是 POP 点是一定知道位置的), 所以可以使用它的 POP 点.
D. Sprint Dataset
by Looking Glass server
3. GeoBud
A. 老三样: PlanetLab, NLANR AMP, RIPE
4. Octant
A. PlanetLab
B. some traceroute servers
A public traceroute server dataset consisting of 53 traceroute servers maintained by various commercial and academic institutions in North America
The individual traceroute server owners specify the location of their traceroute servers as part of the traceroute service.
5. Structon
A. database
we use ip.cn, the grassroot generated IP geolocation database as our ‘groundtruth’.
Our experiences showed that ip.cn is quite accurate, though it needs huge amount of human involvement
6. GeoWeight
A. PlanetLab
7. MLE
A. PlanetLab
8. Learning
A. Database(MaxMind)
9. Spotter
A. PlanetLab
B. Cogent IP
- 虽然说了是 CAIDA 的数据集, 但是后面的引用里面只有 CAIDA 这个组织名称, 而不是那个数据集下载位置.(TODO)
To investigate the methods in a more realistic scenario we use a more representative data set collected by CAIDA [4] for the purpose of a geolocation comparison survey.
This data set contains more than 23000 distinct IP addresses geographically distributed across North America and Europe.
These IPs belong to network routers of Cogent, a large Tier-1 ISP. We refer to this data set as COGENT.
C. YouTube Server Location(这个没有用来检测错误率, 忽略它)
In this study we focus on IP addresses belonging to the 74.125.0.0/16 address block serving most of the YouTube contents.
The next use case shows that the locations of these content delivery centers are in accordance with the largest Internet junctions traversed by the significant fraction of end-to-end network paths.
10. SLG
A. PlanetLab
B. Volunteers: 72 IPs
原文是 residential set, 其实就是志愿者贡献. 建立一个网站, 让用户输入他们的住址和 ISP 等信息, 同时网站也会自动记录 IP 地址. 小细节: 如果用 VPN, 用户不准输入地址.
C. OnlineMap dataset
从一个在线地图服务中获取了日志数据. 每个日志有用户 IP, 用户浏览器, 源位置和目的位置. 然后处理这些数据, 将 IP 和地理位置绑定.(比如要看这个 IP 是否一个月能有好几次都和某个位置相关, 比如要删除那些用了多个浏览器的 IP, 因为不清楚该IP地址是仅由一个具有多个浏览器的用户使用,还是由不同的用户使用)
11. Posit
A. Akamai Set
We use a set of measurements collected from 431 commercial hosts with known latitude/longitude coordinates that belong to Akamai Technologies in North America.
B. DNS LOC Set
We also consider a set of 283 hosts with domain names that include valid DNS LOC records in the continental United States.
12. DRoP
A. Owners: Operators
We obtained ground truth from operators responsible for 6 public suffixes who shared their router naming schemes: akamai.com, belwue.de, cogentco.com, digitalwest.net, ntt.net, and peak10.net
13. Checkin-Geo
A. Volunteers
和 SLG 一样的方法, 弄一个网站, 让人来输入信息.
14. Alidade
A. PlanetLab
B. Ark
C. MeasurementLab
D. GPS
E. NTP
F. EuroGT
The EuroGT ground-truth data is a list of city locations for approximately 24 million IP addresses provided by a European Tier-1 network provider.
15. BroadBand
A. Database
Since no ground truth about Korean IP geolocation data is available, we examine the accuracy by comparing the distance difference with other DBs.
16. Query
A. Owners: Query
Mobile applications can request access to real time location information in order to provide better results. While not all users are comfortable with sharing their location, a representative set of users agree to provide this information. We use this information from search engine logs to generate the ground truth set
(TODO, 后续会进行去除一些数据, 话说它用 query log 来评测用 query log 推测地址的方法, 这...)
17. Shopping
A: Database
Table 2
18. BigData Reverse DNS
A. Owners: Query
就是和 Query log 那篇文章一个作者..
We compiled the ground truth set in March 2018 by randomly sampling the query logs of a large-scale commercial search engine.
19. XLBoost-Geo
A. PlanetLab
B. RIPE
20. GeoCAM
TODO
21. Interpolation
A. Owners: Query
Our proprietary ground truth set contains 8.9 million IP addresses with known location, compiled during the 28-day period ending on December 1st, 2017 from Bing query logs
22. Millions
A. PlanetLab
B. University
23. Geo-NN
A. RIPE
B. University Websites
Academic institutions are believed to have a higher chance to host their web servers locally.
筛选: 使用 Whois 信息筛选出名称中不包含 "university", "college" 或 "institute" 等关键字, 但拥有来自不同大学的多个 IP 地址的组织
缺点: However, their coverage is more dense in the Eastern US and on the western coast, leaving gaps in Mid-west areas
C. City Dataset
We assumed that bigger cities with more population had higher chances to host their web servers locally.
We chose top 60 cities from each state, again made use of Google’s Websearch API[10] and applied similar methods that we used to process University Dataset
24. One-Geo
A. PlanetLab
B. RIPE
25. Last Miles Hop
A. RTBAsia Landmark Dataset.
作者说这个数据库 as accurate as GPS geolocation, 确定嘛...
26. GeoCAM
A. CAM
We manually inspected those snapshots of live streams of webcams, and searched relevant geographical contexts in Google Map
Internet2
Internet2 是一个非营利性的美国计算机网络联盟[2], 运营着創立於1996年的Internet2网络[3],这是一个使用光纤的网际协议网络,美國不少大学和研究机构使用該網絡[4][5]。
Q1: 运营商的拓扑结构我们知道
PlanetLab nodes insufficient: all located on academic networks, needed to validate our approach on residential networks (or other) as well.
Every set should be filtered, by active probing...
Existing data were provided by the iPlane project [1], which performs a traceroute from all available PlanetLab hosting sites to a set of target prefixes obtained through the Routeviews project.
📁 method
📄 2004_IMC_CBG.txt
IMC 2004, A
想法
1. 需要做实验, 他的实际预测情况究竟是什么样的?
2. 即使得到关系后, 因为测量目标时的 RTT 不可靠, 要测多次选最快的, 那么需要测量多少次呢?
方法
1. 经典的三角定位
2. baseline 是 y=kx, 其中 k 就是 2/3 光速
3. bestline 是以最快的点为基准, 因此比较包容
📄 2006_IMC_TBG.txt
1. 网络拓扑对 IP 定位的作用
- 图6, 如果是左边的拓扑图, 换算很正常; 但是右边的拓扑图, 就会发现估计的半径肯定更大, 因为时延是 (x->u->z), 不是直接的(x->u). 因此我们能先定位到 u, 然后再去定位 z, 效果更好. 所以定位一个 target 可以先定位中间路由器, 然后定位它.
- 图7, 别名解析的好处了, 图非常直观, 不解释了.
- 图8, 即使考虑到网络拓扑, 纯基于测量的技术也存在固有的局限性. 这个 Alabama 只有两个路由器,它走出去是通过这个 SOX 路由器(SOX 就可以理解为一家公司). 所以当我们有 SOX 路由器地理位置时, 显然通过主动测量没有办法去获取那两个路由器位置, 因为相当于只有一个 VP, 缺少了限制. 此时要结合其他方法,比如 Landmark 等等。
2. 评价
- 网络拓扑确实有作用, 不过因为 TBG 实现不是很懂, 没感觉出它用上了拓扑
3. 具体的方法
- 首先使用 traceroute,这样可以获取整个网络的拓扑图,而且每一条的 hop-latency 也可以获取
--- 每一跳的 hop-latency 可以获取?traceroute 如果发送和返回是不同路径,该怎么办,这个可是经常发生。
三种方法 TODO (MARK: 4.2.1)
--- 然后是别名解析的问题,怎么处理?
就是使用 Mercator 和 Ally
--- TBG 使用了解析一些路由器 DNS,从而推测位置,怎么减少误报率?
有很多方法。第一,通过拓扑关系,就是拿一个【比较近的路由器 A 】去探测【解析的路由器 B】,预先设定好 RTT,如果 B 不在该位置,那就不会返回,所以出错。第二,通过别名解析,假如 A 和 B 都解析到了一个位置,可能 A 和 B 是别名,然后用别名解析的方法去推测是否真的是别名。第三,就是通过主动测量来看看位置是否一样,假如 A 解析得到一个位置,现在我们再去用不同的路由器主动测量 A,去获取它的位置范围,看看是否是解析得到的这个位置,如果大部分路由器都是一致,那么就说明真的就是这个位置。
- 获取了整个网络拓扑图,现在就是具体的推测方法
TBG 就是转换成一个公式。约束条件也比较容易理解。
但是还需要额外补充几点。第一,要考虑相对误差,即【预测 10km,偏差值是 1km】和【预测 100km,偏差值是 2km】,肯定后者更好,但是公式中会选前者。第二,在 4.2.1 中提到,有些路径的测量值是更加准确的,所以要有一个线性因子,用来考虑这些路径准确性的不同程度。第三,公式中是考虑每个 Hop,还需要考虑一条 Path 的估计值不要超过某个范围。
现在有一个问题就是: h(i,j) 是什么东西,他表示距离,那么它是怎么从 latency 得到的呢?
TODO: 4.4 需要在看一下
📄 2006_NETWORKING_GeoBud.txt
Networking 2006, B
想法
1. 其实每个探测点到每个终点受到的影响不一样, 这个想法很好, 但是文章的处理似乎太粗糙了, 能否和后续的分段且每段有概率的方法结合?
1. CBG 是对于每个探测点计算 y=mx+b.
GeoBud 认为对于一个探测点而言, 它到每个终点受到的影响是不一样的.
比如: a->b->c, a->b 会损失 1s, b->c 会损失 1s, 那么 a->c 会损失 2s.
所以不能笼统的把各个终点测的值归为一条直线.
这篇文章同样认为每一个 (VP, Target) 有 y=mx+b, 但是含义不一样, 他们含义如下:
- y: 时延
- x: 地理距离
- m: 固定为 2/3 光速的二倍(因为时延是往返,所以要二倍)
- b: 补偿值
所以主要是 b 如何计算.
这篇文章有点扯, 它是通过对 traceroute 中每一跳节点都挨个计算, 如果能够全部定位, 那么就根据每一条的 RTT, 得出每一条的 b, 然后加起来就好了.(最后一个 b 是 0)
📄 2007_NSDI_Octant.txt
NSDI 2007, A
3. 评价
3.1 有的细节非常好, 以下: 远的地标权重要小, 中间路由器协助定位
3.2 虽然很好的方法, 但是没有什么好的思路啊..
1. 总体评价
最直观的就是圆变成圆环了,当然这是理想情况,正常的话还有贝祖曲线,还有许多细节考虑。
2. 一些问题
2.1 最低和最长距离怎么得到
图 4 而言, 最长距离就是 凸包上界, 最短距离就是 凸包下界. 当然这种可能偶尔会出错.
因此还要考虑某一个竖线, 左边还是按照上下界来评价, 右边上界是光速, 下界是水平线.
2.2 最后一条时延
TODO
2.3 Indirect Path
这个是和 TBG 一样的考虑。举个中国例子(我瞎编的): 南大和东南两个终端交互,结果要从教育网先从南京到济南再到北京,然后从北京回济南回南京。测得距离会非常大,约束条件太宽松了。
方法一样的,就是先测出中间路由器,测量方式可以加入别的因素。比如路由器嘛,可以使用 DNS 反向解析,如果从中抽取出 zipcode,那就直接可以定位非常精确了。
如果中间路由器没有这些信息,因此只能推测这个路由器在一个区域的话,Octant 也可以利用这个区域来推测的。(看图 3)
2.4 不同的地标有不同的准确度
距离远的 Landmark 测得延迟准确率会相对比较低。(WHY: 路径曲折、路径更加拥挤)
所以说明延迟越大的,权重就要相对较小一点,Octant 中权重随着延迟增加而指数下降。
这个权重是什么意思呢,就是 Octant 的每个环有不同的权重,最后就取哪些叠加起来比较大的区域。
2.5 约束条件是强还是弱
从 1 中可以看到,约束条件有强有弱,比如只看光速三分之二,比如直接是凸包上下界。
约束条件越强肯定定位越好,但是也可能过头了导致空集。
所以 Octant 就有一个属性值,你可以选择什么样的约束条件。
2.6 额外的限制
如同其他的方法一样,Octant 也不仅局限于时延的约束条件。
Postive Constraint: zipcode(TODO)
Negative Constraint: 海洋、沼泽这些不可能的位置
因为有贝祖曲线,可以表现任意形状,所以非常好表示这些五花八门的约束条件。
2.7 从区域中找出最可能的点
因为 Octant 最后给的是区域嘛,所以还是可以再进一步去看看这个区域中哪个点最有可能是目标位置。
使用蒙特卡洛方法去寻找这个点,其实就可以错误地理解为找区域中心点。
如果不是前人方法是返回一个点,估计 Octant 不会这样多此一举。
具体方法如下(不用细看):首先选择区域内的数千个随机点,根据每个点到其他选定点的距离总和,为每个点指定一个权重。经过一定次数的试验,选择权重最小的点作为目标位置的最佳估计。
📄 2009_ICCCN_Statical.txt
灌水
就近原则, 三角定位, 极大似然估计, 朴素贝叶斯
📄 2009_IMC_Proxy_Geo.txt
主要创新点是研究如何定位 Proxy 的位置.
因为难点就是无法在 Proxy 上发包, 所以让它成为中介, 原理是图 2, 方法很巧妙.
📄 2009_INFOCOMM_Structon.txt
很好理解的方式, 就是通过挖掘网页内容来获得物理地址.
想法
1. 从网页提取内容, 这个似乎已经做烂了, 暂时没有从这个做法中得到什么
2. 倒是它的扩展更高段方法很有启发, 比如: Fig.1 这样的规则是从何而来的, 我换个规则是不是效果更好?
3. 和 BGP, AS 结合, 这两个我觉得一定可以再挖掘, 不过现在没有想法, 先记着
1. 第一步
利用正则表达式从网页中提取内容. 可以利用一些 weight, 比如从网页底部抽取出来的内容更有可能是真的地址.
2. 第二步
从网站抽取地址后, 网站有 DNS 域名, 因此可以得到 (DNS, Location) 这样的向量, 具体可以看 Table 1
DNS 又有可能又多个 IP, 这个时候每个 IP 都会继承 (DNS, Location) 那个向量. 如果一个 IP 有多个向量, 要取平均.
3. 第三步
3.1 推测 /24 段 的位置
把之前的 IP 按照 /24 分组, 然后按照 Table 2 的方法来获取概率值, 最后我们就可以得到某些 /24 段的位置了
3.2 推测 更高段 的位置
- 推测
比如现在要推测一个 /22 段的位置, 它里面有 4 个 /24 段, 根据 3.1, 有的段位置已经知道了, 设为 [S0, S3]
然后就是看 Fig1 的图, 有些情况下可以推测这个大段位置, 有的时候不可以.
Fig1 的图应该这样理解: 先忽略绿色的点, 剩下的 L 就是我们知道这个段位置是 L, 因此我们就看这个大段对应图中哪一行, 然后就可以决定能否把其他段给推出来, 能推出来的点就是绿色的那些 L...
这个是可以递归下去, 比如下次就会推测 /20 段的位置, 所以就是用 4 个 /22 段.
- 检查
推测完之后我们要对这个大段进行检查.
这个大段可以分为很多个 /24 段, 设这个列表为 IPSegList.
Na: 列表长度, Lm: 最多的 /24 段所在地, Nm: 所在地是 Lm 的 /24 段数量.
如果满足下面条件, 就认为通过检查了.
- IPSegList 中一头一尾认为它们的所在地是 Lm
- Na >= n_setting, Nm/Na >= m_setting
如果成功, 那么就可以把这个大段都设为 Lm. 如果失败, 那么就要返回重新去推测了.
3.3 利用其他方式来推测待定段
第一种是利用小型 AS, 因为小型 AS 里面的 IP 很有可能在一个地方. 符合下面条件就可以.
- AS 中的 IP 数目 <= n_setting
- 大部分人 / 总数 >= m_setting
- 最后得出的结果 == whois 中描述该 AS 的所在地
第二种是利用 BGP routing table
S: 一堆 IP 集合
Setk: 这个 S 集合里面已知地址的 IP 集合
Lm: 这个 Setk 集合里面最多人出现的位置
Setm: 这个 Setk 集合里面位置在 Lm 的 IP 集合
cratio = |Setk| / |S|
mratio = |Setm| / |Setk|
看 Fig.2 即可, 下面是一点备注
- 其实这里和 BGP 没太大关系, 就是借助 BGP 路由表里面出现的子网段, 看看能否把它的更细的子网段的位置定位好.
- 为什么不直接从整个互联网段开始呢, 因为作者认为两个相邻的子网属于不同的AS, 这种情况下它们应该很有可能不在同一位置. 所以 BGP 路由表已经帮我们给做了. 因为如果是两个相邻子网并且都是一个 AS, 在路由表里就会合并为一个表项, 所以路由表应该都是不同 AS 的各个网段啦.
📄 2010_ACSC_GeoWeight.txt
就是在距离基础上增加概率因素.
评价
1. 我觉得这绝对是一个非常非常好的思路, 只是这篇文章算概率的方式可能太粗糙了, 能否加入人口等等因素??
📄 2010_PAM_Learning.txt
就是用最简单的机器学习里的回归来完成预测.
相当于每个城市由时延, 人口, 跳数得出一个成绩.
📄 2011_INFOCOM_Spotter.txt
用高斯分布模拟, 我觉得吧, 模拟确实很对, 但是最后得到了一个预测函数, 根据 RTT 进行预测, 这个距离值很显然会有一些偏差的, 如果是偏大还好, 如果偏小那就没有办法了.
所以还是要先得到一个粗糙的函数, 确保在这个范围内, 然后再去精确预测.
📄 2011_NSDI_SLG.txt
NSDI 2011, A
终于是这篇文章了, 除了 CBG 和 TBG 外最经典的文章
1. 云服务器的定位, 这个可以思考一下, 我要先判断一下他是否是云服务器
1. 其实它本质上就是被动挖掘, 从网页地图服务中挖掘出 Landmark, 但是我觉得这个方法可能现在没有太大用处了.
2. 通过 traceroute 计算 (Landmark, target) 之间的距离, 这个想法不错. 因为以前只能计算出 (VP, target) 的距离. 但是这种计算方式有待考量.
📄 2012_CN_Dong.txt
📄 2012_IMC_Millions.txt
IMC 2012, A
主要是来讲主动定位速度选取 VP 的问题.
想法
1. VP 确实对测量结果有影响, 但是我觉得这篇文章太浅了, 还需要继续研究: 是否不同地方的 VP 质量也不一样?
论文阅读
三个关于 VP 的探讨.
1. VP 数目不是越多越好, 到达一定程度就会收敛.
结果:Fig2.a & Fig3.a, 分别对应 SOI 和 CBG, 确实如此, 平均值和方差都是这样(方差就是图中每条竖线的上下点)
2. VP 数目少的时候, 也可能达到很好的准确度.
结果:Fig2.b & Fig3.b
对于每种数量 VP 集合, 随即尝试选择 10,000 次, 然后绘制了下面的图.
可以看到, 虽然选取 5 VPs 有许多时候误差率很大, 但是有时选取的 5 个 VPs 却和选取 50 VPs 结果差不多.
所以说明我们只要能够选取合适的集合, 数量虽然小也没有太大关系.
3. VP 越近越能够定位精准
结果:Fig2.c & Fig3.c
综合上面的结论, 下面进行主动定位.
1. Find Representatives
这篇文章是对每个子网段进行探测(block), 所以在每个子网段选三个代表. 好像是从 hitlist 来选的
2. Select Nearby VPs
让所有的 VPs 去探测 representatives, 然后根据 RTT 选择最近的 VPs
3. Probe Blocks
然后让选取的 Nearby VPs 去探测该子网段的所有地址
4. Retrieving Data and Geolocation
最后用以前的主动定位方式来定位即可
📄 2012_MILCOM_Ehancing_classification.txt
我觉得被引用 15 次挺离谱的.
这篇文章就是在 Learning 那篇文章上加了几个特征...
主要加了时延, 包括 average delay, standard deviation of delay, mode and median of delay and careful selection of landmarks.
📄 2012_SIGMETRICS_Posit.txt
原来的 Geoping 是使用欧几里得距离,本质上这篇文章就是把欧式距离换成别的距离...
对, 这篇文章和 Geoping 一样的, 就是算向量, 然后看看相似度, 看看和哪一个地标更近
换算成什么样的距离?
- 不加限制条件的
- 有限制条件的
最终的定位也做了一下修改,还把 Monitor 的信息加了进去
为什么有勇气认为改完后的距离比欧式距离要好?
📄 2012_TPDS_Geo_China.txt
📄 2013_TPDS_GeoGet.txt
1. 评价
[ 缺点 ]
- 这篇文章是客户端定位, 也就是客户端发包来探测自己的位置.. 这样一看, 这篇文章价值不是很大
[ 优点 ]
- 这篇文章之所以引用高, 因为它的分析方法很好, 用了 "相关系数" 来评价
它指明了一点: "延迟和距离没有线性关系", 但是 "延迟最小,距离最近"
- 和 AS 的结合
如何选取近的服务器, 文章用了选择和 client 同一个 AS 的 Webserver, 因为 相同 AS 一般比 不同 AS 更近
[ 想法 ]
- 延迟最小, 距离最近. 真的是这样吗? 需要好好的分析
- 和 AS 结合, 这个记下来, 算是最后的一些优化方法
2. 总体介绍
利用 JS 代码,地标选择全部是 WebServer,客户端执行 JS 去访问这些,根据返回时间近似位置。
3. 细节
它的优势就是 Webserver 可能不支持 ICMP,但是基本上都是支持 HTTP/Get 的。
它这个我觉得非常明显的缺陷就是,是 客户端 发起定位。意思就是只满足【客户端去定位自身】这个要求。
1. 首先客户端去请求一个 Web Page,这个 Web Page 理解成 WebServer,它有一段 JS 服务代码。客户端访问后就会在客户端自己上面执行这段代码。
2. 然后客户端执行这段代码,行为是访问一些 Webserver,并且会记录返回时间。这些 Webserver 的位置都是事先知道的。
3. 所以最后就通过返回时间,看一下哪个 Webserver 更近,就近似为这个地址。
4. 它也是先约束到一个区域,然后在区域里面去精细位置。
- Webserver(passive landmarks) 怎么找
To collect webserver landmarks, we have crawled a huge number of webservers in China and got their IP addresses.
Then, we check the geolocations of the webservers by multiple IP-geolocation mapping databases. Only those webservers whose geolocations are agreed by all the databases are chosen as passive landmarks in our system.
Finally, we get 43,973 webservers as passive landmarks. The webservers cover 336 cities, out of a total number of 346 cities in China. The coverage ratio is 97.1 percent.
Considering that the Internet popularity in China is uneven, there may be a few clients coming from cities where we cannot find any webserver. But overall, the coverage ratio is adequate for most locality-aware applications.
- client 如何选择去访问不同、距离近的 Webserver?
加入了一个 Coordinate Server,是我们实现的一个 Webserver。这样当 client 访问我们的 webserver 得到了 js 代码后,会先访问 Coordinate Server。
比如说现在限定在区域 A 中,Coordinate 就会选取区域 A 中的一些 Webserver,然后返回给 client,client 因此得以访问不同的 Webserver。
如何选取近的?比如可以选择和 client 同一个 AS 的 Webserver(因为同一个 AS 一般比 不同 AS 更近)
- TODO: 确定【延迟最小,距离最近】这个真的这样吗?
📄 2014_CCR_DRoP.txt
- 路由器从何得知?
CAIDA Ark traceroute data && CAIDA ITDK data
- DNS hostname 从何而来?
CAIDA ITDK data
- 有哪些地点提示?
从五个数据库中抽取:IATA code(aircode),ICAO code(aircode),CLLI code,UN/LOCODE,一些操作员会直接在名字中添加城市名
- 如何消除世界上可能不同地方的名字是一样的
利用主动测量的时延。
In Arck data, each ip address has associate RTT and TTL from reply packets arriving at Ark monitors.
- 具体步骤
1. 对 hostname 分割
2. 利用时延排除一些 geohint
- 对于输入,如何从数据集中找出它可能的城市,使用正则表达式吗?
缺陷
- 数据集还不够多,但是这个方法是非常新颖的,只要数据集越多,那定位就越多
📄 2014_INFOCOM_CheckinGeo.txt
根据用户签到.
1. 24 段真的在一个城市嘛
2. 它没有是一个 IP 去定位, 而是直接通过 24 段来进行定位, 这个可以效仿
📄 2016_CCR_Broadband.txt
通过用户测速会上传位置, 从而进行定位.
1. 没什么借鉴的, 包括 IP 扩展, 就是那种最朴素的投票方式
📄 2016_INFOCOM_WKSHPS_GeoNN.txt
这个重点在于 Landmark 的获取, 获取之后就是使用神经网络玄学训练了...
数据在 data 目录里也记录了, 这里也写一下吧.
A. RIPE
B. University Websites
Academic institutions are believed to have a higher chance to host their web servers locally.
筛选: 使用 Whois 信息筛选出名称中不包含 "university", "college" 或 "institute" 等关键字, 但拥有来自不同大学的多个 IP 地址的组织
缺点: However, their coverage is more dense in the Eastern US and on the western coast, leaving gaps in Mid-west areas
C. City Dataset
We assumed that bigger cities with more population had higher chances to host their web servers locally.
We chose top 60 cities from each state, again made use of Google’s Websearch API[10] and applied similar methods that we used to process University Dataset
筛选: 同 University Websites
📄 2016_WSDM_QueryGeo.txt
原理很简单, 就是通过搜索引擎记录来进行定位, 下面讲一下注意点.
1. 首先就是: 误报率似乎很高. 比如我在北京, 想去上海旅游, 就会搜上海的旅店, 很显然就出错了吧.
解决方式是不对应一个地址, 而是一个地址段, 这样就能得到一个地址段的各种记录, 这样保证了正确性.
2. 用户为什么会加地址信息?
- 用户个人习惯, 用户不知道搜索引擎知道他们的位置
- 用户发现搜索引擎搜的不好, 就增加了具体的位置
- 用户想搜索一些其他城市的信息(这个增加误报率, 而上面两个是好的, 增加覆盖率)
📄 2018_IMC_GeoVPN.md
# 论文阅读: How to Catch when Proxies Lie
1. 我觉得需要那 Octant 和 CBG 进行比较, 看看为什么它预测保证准确度比 CBG 差很多.
2. 感觉 CBG++ 那里还是有些粗糙哦..
## 保证预测区域一定正确
这篇文章其中一个比较引人注意的是, 他提出了一个保证预测区域是正确的算法, 虽然区域可能会很大, 但是至少我把区域从全球缩减为了一小块地方.
### slowline
首先很重要的一点, 这篇文章指出了为什么预测区域会不准确, 就是因为有很多时候 RTT 要超过正常时间!
这篇文章提到, CBG 设置了速度上限, 那是否可以设置速度下限? 实际上这个和 Octant 有点像.
但是设置了 slowline 也无济于事, 仍然有很多是在预测区域外.
### CBG++
然后作者就提出了一种新的方法.
1. 首先不是从 bestline 进行定位, 而是从 baseline 开始确定区域, 因为 RTT 在如何扩大也不会扩大到 baseline 那里.
2. 然后开始检测 bestline, 如果 bestline 涉及到了确定的区域中, 就会保留这个 bestline, 直到遍历所有 line.
📄 2019_IWQoS_LastMileHop.txt
IWQos 2019, B
槽点
1. 使用的数据有问题, 直接用了 RTBAsia Landmark Dataset, 虽然它声称自己和 GPS 一样精确度, 但明显不可信.
2. 比较 Hop and RTT, 两个地表之间是传播的时候是曲折的, 计算却用笔直的距离..
3. 评测的时候, 保证 Landmark and Target 在同一个地方, 但是实际评测并不能确定 Target 在哪里
4. 太依赖拓扑了, 感觉拓扑本身就有很多问题
想法
1. 得出路由器覆盖范围, 那能否就利用主动定位来判断?
2. 一定要好好思考这篇文章
这篇文章很有启发
1. 中国网络的特殊性
中国的网络是由几个大 ISP 组成的, 这些 ISP 进一步分层, 巧妙地组织成国家主干网和地区/省级网络.
由于 ISP 屏障的存在, ISP 之间的互联互通性非常弱, 这是独特的, 不同于美国和欧洲.
带来的结果: A path between a landmark and a destination can often be circuitous and inflated by queuing and processing delays
调研中国的网络
- Attempt to Acquire Landmarks
想效仿 SLG 的方法, 但是效果不好, 代价也很大
- RTBAsia Landmark Dataset
We directly acquire our landmark dataset from RTBAsia. Based on the dataset description, it is as accurate as GPS geolocation.
- RTT
RTT 效果不是很好, coeffeciency 太低(TODO: 但是我没有理解 Fig 3)
2. Hop
- 我们观察, 与 RTT 相比, 跟踪路由和跳数更稳定, 来自一台服务器的单个跟踪路由请求就足以进行准确的物理距离估计.
- 在一个省或市内, 普通以太网仅限于光纤上几公里的距离, 因此有机会结合跳数来优化 IP 地理定位精度
- 如果最后一跳是同一个路由器, 那基本上距离非常接近, Fig4.a
- 现在扩大化, 不要求最后一跳是同一路由器, 而是寻找每个 Landmark 对的 last common router, 根据他们之间的距离和跳数, 得到路由器的覆盖范围, Fig4.b
- 类似于上一个, 上一个用 Hop, 这个用 RTT, 根据两个 Landmark 之间的距离和 RTT, 算出传播速度, Fig4.c
- 上面两个, 就是想证明: Hop 比 RTT 稳定, 从两个结果的 coefficient of variation 来看, Hop 比较小, 说明更稳定
TODO: 但是两个地表之间是传播的时候是曲折的, 计算却用笔直的距离..
3. 计算
- 用一台机器去 traceroute, 得到拓扑图
- 找到 (Landmarks, Landmarks), (Landmarks, Targets) 之间的 shortest Hop Path and last common router
- 计算每一台 router 的覆盖范围, 方法就是根据 (landmarks, landmarks) 之间距离再除以跳数, 有多个对那就取平均
- 根据 last common router 覆盖范围 + 对应 Landmark, 推出 Target 的 距离. 很明显, 有多个距离就取最小值.
📄 2019_WASA_OneGeo.txt
原理是通过 owner name
想法
1. 方法挺离谱的, 不值得借鉴.
2. 倒是扩展的方法很有思路, 可以想一想, 现在暂时想不到改进的地方: leader 只有一个合理嘛
1. 获取 Owner name(orgnaization): WHOIS / Website
2. 获取 Owner name location: Data center map, yellow page ...
3. 如果超过一个候选地址, 那就要继续接下来的操作.
4. 使用 CBG 过滤候选地址, 如果超过一个, 继续接下来的操作.
5. 这个就不写了, 感觉先不用看
6. 子网段 扩展
dominant group: 一个 /24 段中 detemines dominant location 的 IP 集合
leader: 离 dominant group 中心点最近的点
followers: dominant group except leader
loners: 24 子网段剩下的点
两个规则来决定是否该 IP 确定位置
1. 计算 (This_ip, leader), (leader, followers) 的时延, 如果 (This_ip, leader) < max(leader, followers), (即最远的 follower 到达 leader 时延), 则合理.
2. 计算 (This_ip, followers), (This_ip, loners) 的时延, 如果: min(This_ip, followers) << any(This_ip, loners), 则合理.
PS: 远小于在本篇文章定位 (5 times less).
📄 2020_CCR_IPMap.md
# RIPE IPmap Active Geolocation: Mechanism and Performance Evaluation
## 想法
1. 选取 100 个最近城市, 太草率了, 如何实现近距离的定位?
2. 使用同一个 AS 的探针, 看起来是考虑拓扑, 那能否直接考虑 traceroute 路径?
分为两个步骤, 一个是如何选取探针, 一个是如何主动测量
## 产生集合
这一步产生两个集合: AS 集合(设为 A), 城市集合(设为 C)
1. Add AS(t) to A.
2. Add to C the cities where AS(t) has a probe.
3. Add to A the ASes neighbors (BGP distance 1) of AS(t).
4. Add to C the cities with Internet Exchange Points (IXPs) where AS(t) is present.
5. Add to A the ASes present at the IXPs identified in step 4.
6. Add to C all the cities corresponding to the facilities where AS(t) is present.
7. Add to A the ASes peering at facilities identified in step 6.
## 选取探针
这一步选取至多 500 个探针
1. Select up to 100 random probes from AS(t);
2. Select up to 10 random probes from each AS in A;
3. Select up to 50 probes for each city in C.
## 筛选城市
1. 上一步得到的探针集合, 进行探测, 选取最短 RTT 的探针, 所在城市为 p
2. 选取地理距离离 p 最近的 100 个城市
## 城市排名
上一步中选取了城市集合, 这一步最终确定可能的地点.
下面是要考虑的三点, 分别赋予不同的权重, 然后计算.
1. the distance of the city (其实就是时延)
2. the number of facilities and IXPs present in the city
3. the population of the city
📄 2020_XXX_XLBoost.txt
这篇文章原理也是利用了抽取网页来获取地标这一方法,SLG 和 Structon 也是这种方法,不过都有缺点。
- SLG: TODO,它的缺点: 定位数量太少
- Structon: 采用正则表达式,因此很粗糙,顶多是城市级别,处理街道级别就很难了。它的缺点: 定位太粗糙。
主要分为下面几步
1. 寻找有对应网页的 IP
2. 过滤掉那些不是本地服务器
3. 使用强化学习方式去抽取得到网页内容中位置信息
4. 有了位置详细信息后,通过地图进行搜索定位
1. 寻找有对应网页的 IP
就是去探测所有 IP 呗,使用工具是 MASSCAN (就是一款类似 ZMap 的扫描工具), 然后访问 443 和 80 端口.
2. 过滤掉那些不是本地服务器
通过 Whois 数据库查询 IP 的组织。然后,通过代理提供者黑名单,我们过滤掉不在本地托管的代理服务器
3. 抽取得到网页内容中位置信息
- 利用强化学习的方式,也没太看懂,模型原始叫做 LSTM-LSTM-Bias,它改完叫做 LSTM-Ada
- 我感觉他就是抽取 Copyright 这种格式,所以可能直接用正则表达式就可以了?
4. 通过地图进行搜索定位
这步看起来好像很容易,但是上一步的结果不一定就完全是详细街道信息。实验发现好多最详细的都是机构名,在地图上非常可能有好几个地方。(即使抽取得知它的国家、城市信息)
所以下面就是从这些候选位置中进行选择,会对每个候选位置进行打分,选择分最高的。
每个候选位置都找到它附近的 Probe 和 Landmark,用于接下来评测(分)
候选位置 ti 的分数为 [公式 11], 下面慢慢对这个公式讲解.
- 首先 s(lj) 表示地标的得分, g(lj, cj) 就可以把它当成每个地标的权重
1. g(lj, cj) 权重怎么来呢, 看 [公式 12], 就是通过距离换算而来
2. s(lj) 表示地标得分, 这个怎么算? 看 [公式 13], 其中 sd(li) 和 st(li) 表示不同的视角时的分数.
3. sd(li) 是按照时延视角来看问题, 计算方式为 [公式 14, 15], 其实公式 15 就表示地标和目标的时延向量余弦相似性
4. st(li) 是按照拓扑视角来看问题, 计算方式为 [公式 16], 其中 r(l, t) 就表示相对的跳数
📄 2021_CoNEXT_LearnRDNS.txt
CoNEXT 21, Learning to Extract Geographic Information from Internet Router Hostnames
从路由器 hostname 中抽取地理信息, 没想到还能玩出花来, 这我是真的没有想到.
本文最大创新点就是可以学习到一些不再预先存储字典中的 geohint, 下面进行总结. 还是先总结如何从预先存储的字典中抽取 geohint, 然后再总结它又是如何做到判定出字典中没有的 geohint.
- 如何抽取 geohint
1. 准备数据集
1.1 Location Dictionary
大部分和 DRop 一样, 但比 DRop 多的一点是他会从 PeeringDB 中的机构名字中抽取 街道名等等
1.2 Router List
CAIDA's ITDK
1.3 Suffix List
Mozilla Public xx, 这个是用来判定后缀的, 因为不同后缀会采用不同的抽取方式. 举例来说, 如果 .com 有后缀 a.com 和 b.com, 那么 xx.a.com 和 xx.b.com 中操作员命名习惯方式可能不一样; 如果 .top 就它一个后缀, 那么 xx.a.top 和 xx.b.top 实际都是 xx.top, 所命名习惯方式都是一样的.
1.4 RTT Measurement
和 DRop 同理, 需要用主动测量的方式去排除错误的 geohint. 用 Ark 去探测各个路由器, 记录好各个探针到路由器的延迟.
(琐碎1)
2. 检测 hostname 中的 apparent geohint
这一步就是直接字符串比对, 看看 hostname 中包含哪些在字典中存在的词.
下面的说法可能会比较难懂, 可以先不懂看下面的例子:
- 只从 hostname 中提取街道或者城市粒度的词
- 对该词进行 RTT 检查, 方式即比较 (该词所在位置到探测点距离, 以光速传播所用时间) 与 (该路由器到探测点时延)
- 找出该城市对应的国家集合(为什么是集合, 因为可能两个国家有相同城市名字), 看看 hostname 中是否有对应的国家缩写, 最后的输出结果为 (city, [country])
具体细节对着图 6 来讲.
a.
抽取的英文单词中, 有 ntt 和 lhr 是在字典中并且是城市粒度.
检查发现 ntt 不符合 RTT 规则, 排除; 检查发现 lhr 符合 RTT 规则, 保留.
发现 lhr 这个城市所在国家集合中有 uk, 而恰好抽取的英文单词中有 uk, 所以保留国家为 uk. 最终结果为 (lhr, uk).
b.
抽取, 有 edge 和 brussels 是城市粒度, 并且符合 RTT 规则.
发现这两个城市对应的各个国家缩写在 hostname 中都不存在, 所以没法保留国家词.
因此最终结果为 (edge) 和 (burssels)
f.
抽取, 发现有 111eightave 这个词, 这个词在 PeeringDB 中抽取的字典中(1.1), 为 '111 8th Ave', 属于街道粒度, 所以保留.
其他同理
- build and evaluate regex
上面第 2 步是 get apparent geohint, 它爬到的信息比较准确, 但是呢, 它的数量不多.
所以我们要使用 regex 对每个 hostname 进行抽取, 并且抽取的结果进行评价, 如果发现表现很好, 那么就用这个 regex.
regex 例子可以看 Fig.7, 一个 hostname 通过一个 regex 会抽取一些关键词, 所以如果抽取出来的关键词很准确, 那么就 OK.
如何判断是否 OK ? 评价指标如下
TP: regex 抽取出的城市符合 RTT 规则(2) & regex 抽取出了 apparent geohint 的 国家信息(例如 Fig 6.a 抽出了 'lhr, uk')
FP: regex 抽取出的城市违法 RTT 规则(2)
FN: regex 没有抽取出 apparent geohint 的城市信息 | regex 没有抽取出 apparent geohint 的国家信息
UNK: regex 抽取出了不在 apparent geohint 的单词
- 如何学习到没在字典里的 geohint
1. 说明
以 Fig.3 为说明
a, 可以看到第四个 lvs 和它的实际位置不符, 这个是因为过时造成. 因此对于 xx.bb.ebay.com, 我们需要指定 lvs 这个词表示 ash 的地址, 而非它原来的位置.
b, 可以看到第三个不符合实际位置, 这是因为这个后缀的 operator 喜欢用 provider 路由器的位置来命名. 因此对于 xx.ntt.net, 我们需要指定 snjsca 为 sea, us.
c, operator 会自己出于习惯弄一些词来命名. 因此对于 xx.navice.eu, 需要指定 hlm 为 ams, hl.
(琐碎2)
2. 步骤
- 选取那些 regex,
需要选取那些推测比较准确的 regex, 这样这个 regex 推出的"异常"单词很可能是值得研究的.
定义 PPV = TP / (TP + FP). 要求: regex 的 PPV 大于 40% & regex 识别了 至少三个 合法 geohint
- 选取哪些"异常"单词
两种类型: 第一种是 UNK, 也就是不在 apparent geohint 中的单词, 对标 a 和 c; 第二中是 FP, 即违反了 RTT 规则, 对标 b.
- 开始推测学习, 以图 8 为例
首先找到了一个缩写后, 在城市名字的集合中寻找符合要求的城市名. 如 Fig 8.a, 现有的 geohint 违反了 RTT 规则, 而我们找到了三个候选城市名.(琐碎3)
从候选城市名中选取最有可能的城市名, 排序方式是 those known to have a facility (via PeeringDB), then by population, then by TPs. 如 Fig 8.a, 找到三个候选城市集, 发现前两个在 PeeringDB 有 facility, 因此按照人口排序, 发现第一个更好.
(琐碎4)
📄 2021_TON_GeoCAM.txt
2021, TON
还有什么其他的物联网设备???
太厉害了, 我是真没想到竟然可以从网络摄像头的网页里获取 IP, 加上网页本身会给出摄像头的位置, 这就齐全了, 脑洞太大了
最后的结果
1. 16,863 landmarks
📄 2021_WWW_Interpolation.md
# 论文阅读: IP Geolocation Using Traceroute Location Propagation and IP Range Location Interpolation
本质上其实很水, 就两个点.
1. 一个子网段如果有多个 IP 在同一个地方, 那么认为这个子网段在这个地点. 作者对这个进行了很多的分析, 结果到最后就是 24 子网段下有两个就可以...
2. 如果两个点之间时延小于某个阈值, 认为在一个地方.
## 数据研究
首先对这个假设先去做个调查研究, 因为是有微软 Bing 的支撑, 所以它们有足够的 ground-truth 来完成, 羡慕.
### 子网段研究
直接看图即可.

然后进行扩展, 就是子网段下面的已知地址如果很接近, 那么就会把这个子网段都归为它们的平均位置.
- 子网段有多大, 最后定位 24
- 子网段里包含多少 ground-truth, 最后为 2. 算是覆盖率和准确率之间的平衡.
- 子网段里各个 ground-truth 之间的距离最多为多少, 最后为 25 km. 同样是覆盖率和准确率的平衡.
最后的结果为下图, 只要看蓝线就可以了. 他是拿 ground-truth 进行 ten-fold 交叉验证, 横坐标的距离表示预测的距离和实际的距离之差.

效果: 8.9 million --> 392 million
### 时延研究
从 traceroute 中抽取各 IP 之间的时延, 如果以 10 ms 为阈值, 从 ground-truth 中可以抽取 2000 pairs, 然后有 65% 是在 10 km 内. 但是 2000 个太少了, 需要扩大.
下面是另一章的内容, 但感觉放在这里更合适, 就是开始研究如何通过小时延进行扩大的步骤.
- 两个节点如果可扩展时的最大延时, 设为 X
- 源 IP 到这两个节点不能超过的最大延时, 设为 Y
最后的结果为下图. 其中 Traceroute-GPS-HighAcc 表示 (X=2, Y=2), Traceroute-GPS-HighCov 表示 (X=3, Y=9). 从名字可以看出, 前者准确高但覆盖率少, 后者相反.

## 可改进的点
可以看一下下面的表. RMSE 表示 root-mean-square error, 可以把它当作评价稳定的指标. 注意看 Traceroute-PeeringDB, 发现它的 RMSE 很高, 即用这个方法在 PeeringDB 中效果有待商榷, 需要探究其原因.
📄 2022_TOIT_MSrDNS.md
# 论文阅读: IP Geolocation through Reverse DNS
2022 TOIT(thl.B), 作者是 Ovidiu Dan, 老熟人了. Microsoft 和 Lehigh University 共同合作完成.
## 摘要
本篇文章从 DNS hostname 中提取信息, 这个之前的文章也写过. 这篇的特殊点在于分析的比较多, 用了机器学习的方法来进行预测(之前都是用的正则表达式).
## DATASET
### Ground truth
这一部分用于训练, 并且作为最后的评价. 用的是微软 Bing 搜索中用户上传的数据, 很显然这是他们的很大优势.
### GeoName && Suffix List
这个和之前的文章一样, 略.
### Rapid7 Reverse DNS
Rapid7 Reverse DNS consists of reverse DNS hostnames of the entire IPv4 address space.
## RDNS
文章对 RDNS 的占比进行了分析, 结果如下图.

1. 可以看到占比还是可以的, 一共 3.7B 有用地址, RDNS 能有 1.25B.
2. 通过剔除调那些后缀名不再 Suffix List 中的条目, 还有 1.24B, 这些认为是合法的 RDNS, 这里面也有些重复的, 去掉后还有 1.15B.
3. 如果直接搜索地名或者代码, 发现有一些已经能匹配上. 但是显然这种太朴素, 需要有更广更准的方法.
## APPROACH
### Splitting hostnames
1. apply ToUnicode algorithm, 这样可以让用其他语言表示的地址信息清晰的显示出来. *例子: `xn--0rsod70av79j.xn--j6w193g` --> 夏威夷舞.香港*
2. 分离 subdomain, domain, public suffix, 见下图.
3. 分离 hostname, 按照 the dotted elements, the transitions between letters, numbers 三层顺序来完成, 构建了一棵树, 见下图.
4. 去除那些只有数字的叶子节点, 去除那些 common terms related to connection characteristics, such as dsl, fiber, and nas, 见下图.


### Features
这一步对着下面的图来讲
1. 切分好的 hostname, 对照着 Primary Feature 这个表, 看看每一个特征能不能找到候选地址.
2. 有了候选列表后, 对照这 Secondary Feature 这个表, 看一下候选地址是否能有对应的特征.
3. 因此将 hostname 和对应的候选地点以及候选地点有哪些特征, 放入分类器中训练.

下面是对这个表的一些解释.
1. No Vowel Names: 去掉元音
2. Admin: administrative region, 行政区域
📁 nettype
📄 0.txt
2017_CCR Dissecting Last-mile Latency Characteristics
2017_IMC Cell Spotting: Studying the Role of Cellular Networks in the Internet
2017_CoNEXT Identifying and Analyzing Broadband Internet Reverse DNS Names
2020_IMC No WAN’s Land: Mapping U.S. Broadband Coverage with Millions of Address Queries to ISPs
📁 note
📄 5-1.md
## Location Accuracy of Commercial IP Address Geolocation Databases
### Introduction
主要有三个贡献
1. 我们的 groudtruth 保证没有错误, 因为是通过 GPS 准确定位来构建的.
2. 我们的 groudtruth 包含了各种类型的城市, related work 的那些 groudtruth 都是通过大城市而来, 因此我们的数据集可以让我们窥探到城市规模和人口对定位的影响.
3. 当定位同一 ISP 中的节点时, 发现虽然两个位置不一样, 但是它们的定位结果却显示很相近. 所以我们特别地从 ISP 分配节点的角度来思考定位在哪带来的影响.
### IP Geolocation 方法总结
直接拿分配机构(IANA->RIR->NIR->LIR->ISP)维护的 IP 信息数据库来获取信息
1. 没有官方的规则说来规范 IP 的信息, 因此相应的位置信息也不是很好, 错误也很严重
2. 这里面的信息太粗了. 比如有的 ISP 在全国范围内部署一段 IP 地址, 所以它的位置就是国家
通过 DNS 来获取信息
1. 没有官方的规则来规范相关的名称信息
2. 有的 DNS 会记录 LOC, 即位置记录(经度纬度), 但是很显然数量少, 而且存储的信息也有很大的偏差
网络主动探测
被动信息收集
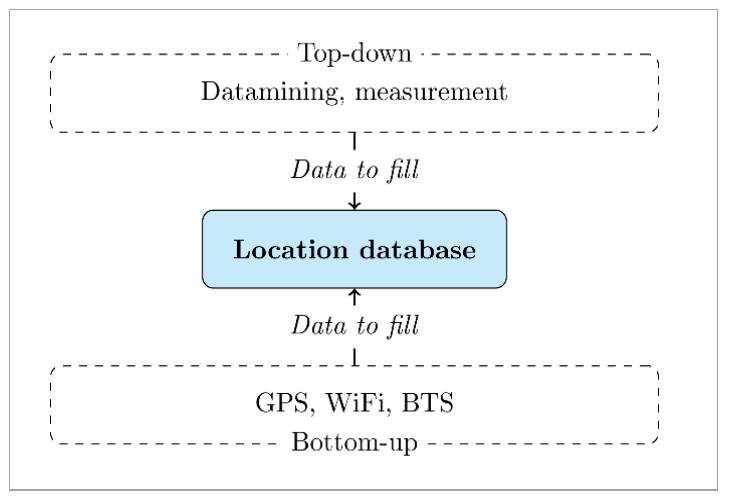
1. 主要分为两种方法, top-down & bottom-up. top-down 就是诸如网页信息挖取等等, bottom-up 就是通过 GPS, WIFI.
### 数据库对比
### Related Work
📄 some.md
IP 定位的用途
(5-1, P2, 1)
1. 社交网络中, 检测虚拟身份滥用和用户名 / 密码 共享
2. 登录服务中, 检测异地登录
3. 电子商店中, 检测信用卡欺诈
4. 银行业务中, 防止网络钓鱼攻击
5. 电子内容中, 实施数字媒体规定的地域限制
总结一下
1. 检测异地登录防范安全(社交网络, 金融银行)
2. 电子内容中, 实施数字媒体规定的地域限制
📄 totoal.md
IP 地理定位
- 应用
- 目前的方法
- 目前的评测
📁 xinda
📄 6-2.txt
其实看 187 页的图就明白了.
实际上就是 Geoping Plus 吧, 把地表聚集成各个大一点的簇, 然后定位到哪一个簇
📄 7-2.txt
原理
1. 根据 traceroute 路径得到 Target 最后一跳路由器相同的 Landmarks
2. 假定最后一跳的 (时延, 距离) 是 y=kx, 然后用三个坐标去定位到最后一跳路由器
3. 把 Target 的位置近似为最后一跳路由器的位置
疑问
1. 很明显, 最后一跳的时延和距离关系应该不是 y=kx, 因为由于它的传输时延很小, 而噪声假设是固定的, 那么传输时延的占比就会很小.
学到的
1. 用相对系数来衡量时延和距离的相关性, 这样就可以得出有的网络下面时延和距离不是线性关系的结论.
📄 7-3.txt
原理
1. 先看 7-2.txt 中的方法, 本文的方法是为了去解决无解的情况. 什么时候会无解, 那就太多了, 因为那个方法要求非常严格, 如果地表有偏移? 如果时延和距离不是 y=kx 关系?
2. 地标的范围变成一个圆, 在这个圆里面取点, 然后看看方程有没有解. 当然点不是圆里面全部取, 比如可以半径递增1km, 角度递增 36'.
3. 如果有多个解, 那就按照 273 页的公式求最小的. 依据是文章认为最近一个共同路由器相连接的地表和目标, 相互之间的相对时延和地理距离是呈比例的.
疑问
1. 文章认为最近一个共同路由器相连接的地表和目标, 相互之间的相对时延和地理距离是呈比例的. 真的是这样嘛?
学到的
1. 地表确实存在误差, 这个怎么克服? 比如说在某个大学, 但是机房的位置肯定是和地图返回的结果有偏差的.
📄 7-4.txt
原理
1. 需要了解 7-3.txt 的方法. 其实就是探讨一个问题: 如果有多个最近共同路由器应该怎么办? 连接最近共同路由器的 Landmardks 没有三个怎么办?
2. Landmardks 没有三个怎么办, 只是不是通过 Landmardks 来定位最近路由器, 而是把它变为连接同一个最近共同路由器的地标的中心点.
3. 有多个最近共同路由器怎么办, 通过取交集. 如果没有交集呢? 那就不断扩大半径, 扩大半径的规则? 直接看 283 页的图吧, (c) 那张图, 左边是 2 个 Landmardks, 右边是 3 个 Landmardks, 所以左边扩大 2/5, 右边扩大 3/5.
学到的
1. 没有将时延转为距离, 这个是非常好的改进了. 之前的方法中, 很显然, 最后一跳并不是 y=kx
疑问
1. 如果是匿名路由器怎么处理? 话说真的最后一跳路由器的各个地址物理距离很近嘛? 需要考察一下.
📄 7-5.txt
原理
1. 为了解决最后一跳是匿名路由器的问题. 还是寻找 Target 和 Landmarks 的共同路由器, 假如是匿名的, 就往前推就行了.
2. 然后多次测量, 分别得到了 Target 和 Landmarks 到那个共同路由器的 (时延-时间) 的曲线.
3. 然后算出各个曲线之间的熵值, 看看哪一个 Landmark 的曲线和 Target 的曲线比较像.
学到的
1. 通过分析曲线类似程度, 这一点确实不错.