泛化和正则化(Chap.8-9)
泛化: generalization, 正则化: Regularization
这里其实没什么说的,都是比较碎的知识。而且到后面很多都是悬而未决的问题。
K fold cross validation
这个还用说吗,就是分成 K 份,然后用 K-1 训练,用剩余的预测。leave-one-out cross validation 是指 K 等于样本数目时,此时每次预测一份。
Online learning
每次来一个 (x(i), y(i)),进行更新
Implicit regularization effect
解释
9.2 节讲的这个,这是深度学习产生的新概念:传统的算法是认为有一个全局的最小值,对于这个优化问题,最终都到达那个最小值。但是深度学习中,却发现很多时候它之后还会有一些下降上升的变化情况,而且不同的学习率也会导致不同的问题。
直接看图解释比较好:
Fig.9.1 先看虚线,能够看到他训练的时候有两个合理的谷底,但是看实现,预测时候左边谷底要比右边的好。
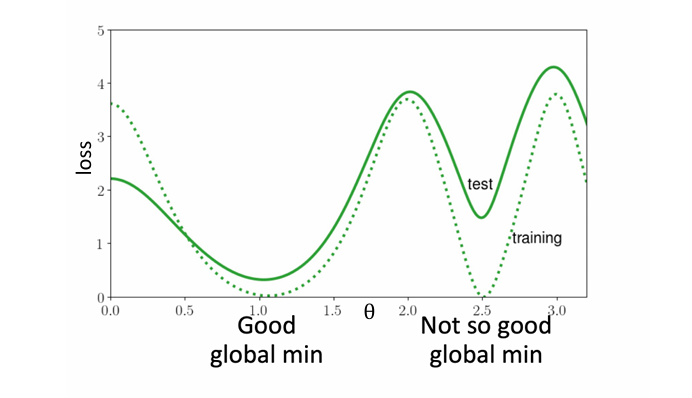
Fig.9.2 先看右边的图,同样的看虚线,两个颜色训练时候最终的 loss 是一样的,结果预测就有区别了。它们的区别只是 initialization 不同。

Fig.9.2 再看左边的图,同样的看虚线,两个颜色训练时候最终的 loss 是一样的,结果预测就有区别了。它们的区别只是 learning-rate 不同。
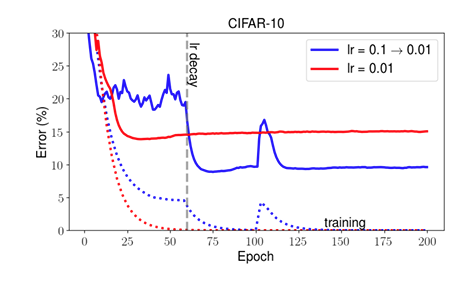
说明
- 这个说明深度学习,我们训练即使得到好的结果,也不能大意,尽量继续再去修改。
- 训练时候的这几个谷底,以及训练时候选择什么 initialization 和 learning-rate,这个都还在要研究中。
- 有一个经验是:大的 learning-rate,小的 initialization,小的 batch-size,小的 momentum 似乎更好
Double descent
model-wise double descent
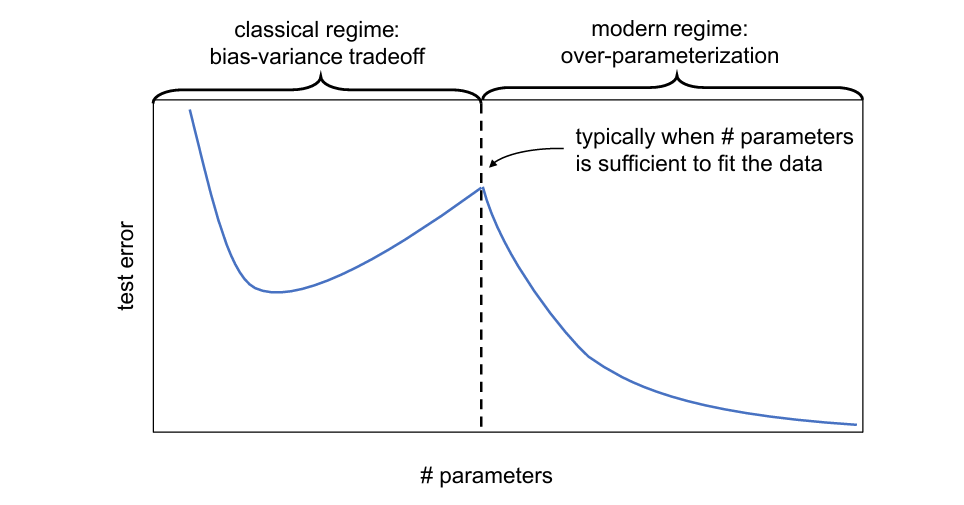
8.2 节介绍,一个在深度学习开始的概念。如下图所示,实际就是当参数数目增大时,会出现 error 降低的现象!而且很多时候,这个第二次降低反而之后会得到更好的结果,而且还没有上升降低上升降低的情况了。(Update:这就是 scaling law,改变世界的一个思想,大模型的思路)
sample-wise double descent
8.2 节介绍,一个在深度学习开始的概念。直观上:训练样本越多越好?可实际情况却不是这样,看图,而且往往是样本数和训练参数相等时候会误差最大。
解决
加入一个比较好的正则项,似乎可以有效减少甚至消除上面的 model-wise 和 sample-wise double descent 的情况。
但真的吗?为什么?以及如何选?这个全在研究中。但是有一个解释是梯度下降引入了上面一章的 implicit regularization effect,导致最终的结果有问题,这个解释没太懂,算了,不强求理解了。
VC 维度
这个太难了,我去