
神经网络量化入门--基本原理


本文首发于公众号

最近打算写一个关于神经网络量化的入门教程,包括网络量化的基本原理、离线量化、量化训练,以及全量化模型的推理过程,最后我会用 pytorch 从零构建一个量化模型,帮助读者形成更深刻的理解。
之所以要写这系列教程,主要是想帮助初次接触量化的同学快速入门。笔者在刚开始接触模型量化时走了很多弯路,并且发现网上的资料和论文对初学者来说太不友好。目前学术界的量化方法都过于花俏,能落地的极少,工业界广泛使用的还是 Google TFLite 那一套量化方法,而 TFLite 对应的大部分资料都只告诉你如何使用,能讲清楚原理的也非常少。这系列教程不会涉及学术上那些花俏的量化方法,主要是想介绍工业界用得最多的量化方案 (即 TFLite 的量化原理,对应 Google 的论文 Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference )
话不多说,我们开始。这一章中,主要介绍网络量化的基本原理,以及推理的时候如何跑量化模型。
背景知识
量化并不是什么新知识,我们在对图像做预处理时就用到了量化。回想一下,我们通常会将一张 uint8 类型、数值范围在 0~255 的图片归一成 float32 类型、数值范围在 0.0~1.0 的张量,这个过程就是反量化。类似地,我们经常将网络输出的范围在 0.0~1.0 之间的张量调整成数值为 0~255、uint8 类型的图片数据,这个过程就是量化。所以量化本质上只是对数值范围的重新调整,可以「粗略」理解为是一种线性映射。(之所以加「粗略」二字,是因为有些论文会用非线性量化,但目前在工业界落地的还都是线性量化,所以本文只讨论线性量化的方案)。
不过,可以明显看出,反量化一般没有信息损失,而量化一般都会有精度损失。这也非常好理解,float32 能保存的数值范围本身就比 uint8 多,因此必定有大量数值无法用 uint8 表示,只能四舍五入成 uint8 型的数值。量化模型和全精度模型的误差也来自四舍五入的 clip 操作。
这篇文章中会用到一些公式,这里我们用 r 表示浮点实数,q 表示量化后的定点整数。浮点和整型之间的换算公式为:
r = S(q-Z) \tag{1}
q = round(\frac{r}{S}+Z) \tag{2}
其中,S 是 scale,表示实数和整数之间的比例关系,Z 是 zero point,表示实数中的 0 经过量化后对应的整数,它们的计算方法为:
S = \frac{r_{max}-r_{min}}{q_{max}-q_{min}} \tag{3}
Z = round(q_{max} - \frac{r_{max}}{S}) \tag{4}
r_{max} 、 r_{min} 分别是r的最大值和最小值, q_{min} 、 q_{max} 同理。这个公式的推导比较简单,很多资料也有详细的介绍,这里不过多介绍。需要强调的一点是,定点整数的 zero point 就代表浮点实数的 0,二者之间的换算不存在精度损失,这一点可以从公式 (2) 中看出来,把 r=0 代入后就可以得到 q=Z。这么做的目的是为了在 padding 时保证浮点数值的 0 和定点整数的 zero point 完全等价,保证定点和浮点之间的表征能够一致。
矩阵运算的量化
由于卷积网络中的卷积层和全连接层本质上都是一堆矩阵乘法,因此我们先看如何将浮点运算上的矩阵转换为定点运算。
假设 r_1、r_2 是浮点实数上的两个N \times N的矩阵,r_3 是 r_1、r_2 相乘后的矩阵:
r_3^{i,k}=\sum_{j=1}^N r_1^{i,j}r_2^{j,k} \tag{5}
假设 S_1、Z_1 是r_1矩阵对应的 scale 和 zero point, S_2 、 Z_2 、 S_3 、 Z_3 同理,那么由 (5) 式可以推出:
S_3(q_3^{i,k}-Z_3)=\sum_{j=1}^{N}S_1(q_{1}^{i,j}-Z_1)S_2(q_2^{j,k}-Z_2) \tag{6}
整理一下可以得到:
q_3^{i,k}=\frac{S_1 S_2}{S_3}\sum_{j=1}^N(q_1^{i,j}-Z_1)(q_2^{j,k}-Z_2)+Z_3 \tag{7}
仔细观察 (7) 式可以发现,除了 \frac{S_1 S_2}{S_3} ,其他都是定点整数运算。那如何把 \frac{S_1 S_2}{S_3} 也变成定点运算呢?这里要用到一个 trick。假设 M=\frac{S_1 S_2}{S_3},由于M通常都是 (0, 1) 之间的实数 (这是通过大量实验统计出来的),因此可以表示成 M=2^{-n}M_0,其中 M_0是一个定点实数。注意,定点数并不一定是整数,所谓定点,指的是小数点的位置是固定的,即小数位数是固定的。因此,如果存在 M=2^{-n}M_0,那我们就可以通过 M_0 的 bit 位移操作实现 2^{-n}M_0,这样整个过程就都在定点上计算了。
很多刚接触量化的同学对这一点比较疑惑,下面我就用一个简单的示例说明这一点。我们把 M=\frac{S_1 S_2}{S_3} 代入 (7) 式可以得到:
q_3^{i,k}=M\sum_{j=1}^N(q_1^{i,j}-Z_1)(q_2^{j,k}-Z_2)+Z_3=MP+Z_3 \tag{8}
这里面P是一个在定点域上计算好的整数。
假设 P=7091,M=0.0072474273418460 (M 可以通过S事先计算得到),那下面我们就是要找到一个M_0和 n,使得MP=2^{-n}M_0 P成立。我们可以用一段代码来找到这两个数:
M = 0.0072474273418460
P = 7091
def multiply(n, M, P):
result = M * P
Mo = int(round(2 ** n * M)) # 这里不一定要四舍五入截断,因为python定点数不好表示才这样处理
approx_result = (Mo * P) >> n
print("n=%d, Mo=%d, approx=%f, error=%f"%\
(n, Mo, approx_result, result-approx_result))
for n in range(1, 16):
multiply(n, M, P)输出:
n=1, Mo=0, approx=0.000000, error=51.391507
n=2, Mo=0, approx=0.000000, error=51.391507
n=3, Mo=0, approx=0.000000, error=51.391507
n=4, Mo=0, approx=0.000000, error=51.391507
n=5, Mo=0, approx=0.000000, error=51.391507
n=6, Mo=0, approx=0.000000, error=51.391507
n=7, Mo=1, approx=55.000000, error=-3.608493
n=8, Mo=2, approx=55.000000, error=-3.608493
n=9, Mo=4, approx=55.000000, error=-3.608493
n=10, Mo=7, approx=48.000000, error=3.391507
n=11, Mo=15, approx=51.000000, error=0.391507
n=12, Mo=30, approx=51.000000, error=0.391507
n=13, Mo=59, approx=51.000000, error=0.391507
n=14, Mo=119, approx=51.000000, error=0.391507
n=15, Mo=237, approx=51.000000, error=0.391507可以看到,在 n=11、 M_0=15 的时候,误差就已经在 1 以内了。因此,可以通过对M_0P右移 n 个 bit 来近似MP,而这个误差本身在可以接受的范围内。这样一来,(8) 式就可以完全通过定点运算来计算,即我们实现了浮点矩阵乘法的量化。
卷积网络的量化
有了上面矩阵乘法的量化,我们就可以进一步尝试对卷积网络的量化。
假设一个这样的网络:

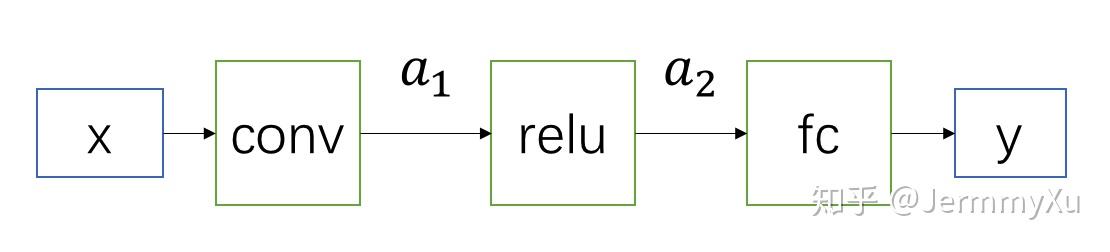
这个网络只有三个模块,现在需要把 conv、fc、relu 量化。
假设输入为 x,我们可以事先统计样本的最大值和最小值,然后计算出S_x(scale) 和Z_x (zero point)。
同样地,假设 conv、fc 的参数为w_1、w_2,以及 scale 和 zero point 为S_{w1}、Z_{w1} 、S_{w2} 、Z_{w2} 。中间层的 feature map 为a_1、a_2 ,并且事先统计出它们的 scale 和 zero point 为 S_{a1} 、Z_{a1} 、S_{a2} 、Z_{a2} 。
卷积运算和全连接层的本质都是矩阵运算,因此我们可以把卷积运算表示成 (这里先忽略加 bias 的操作,这一步同样可以量化,不过中间有一些 trick,我们在之后的文章再仔细研究): a_1^{i,k}=\sum_{j=1}^N x^{i,j}w_1^{j,k} \tag{9}
根据之前的转换,我们可以得到:
q_{a1}^{i,k}=M\sum_{j=1}^N(q_x^{i,j}-Z_x)(q_{w1}^{j,k}-Z_{w1})+Z_{a1} \tag{10}
其中 M=\frac{S_{w1}S_{x}}{S_{a1}} 。
得到 conv 的输出后,我们不用反量化回 a_1,直接用q_{a1}继续后面的计算即可。
对于量化的 relu 来说,计算公式不再是q_{a2}=max(q_{a1}, 0),而是 q_{a2}=max(q_{a1},Z_{a1}) ,并且S_{a1}=S_{a2}, Z_{a1}=Z_{a2} (为什么是这样,这一点留作思考题)。另外,在实际部署的时候,relu 或者 bn 通常是会整合到 conv 中一起计算的,这一点在之后的文章再讲解。
得到q_{a2}后,我们可以继续用 (8) 式来计算 fc 层。假设网络输出为 y,对应的 scale 和 zero point 为 S_y、 Z_y ,则量化后的 fc 层可以用如下公式计算:
q_{y}^{i,k}=M\sum_{j=1}^N(q_{a2}^{i,j}-Z_{a2})(q_{w2}^{j,k}-Z_{w2})+Z_{y}\tag{11}
然后通过公式y=S_y(q_y-Z_y)把结果反量化回去,就可以得到近似原来全精度模型的输出了。
可以看到,上面整个流程都是用定点运算实现的。我们在得到全精度的模型后,可以事先统计出 weight 以及中间各个 feature map 的 min、max,并以此计算出 scale 和 zero point,然后把 weight 量化成 int8/int16 型的整数后,整个网络便完成了量化,然后就可以依据上面的流程做量化推理了。
总结
这篇文章主要介绍了矩阵量化的原理,以及如何把矩阵量化运用到卷积网络中,实现全量化网络的计算。这中间忽略了很多细节,比如 relu 和 conv 的合并、激活函数的量化、量化训练的流程等。后面的文章会继续补充一些细节,并通过从零搭建一个 pytorch 的量化模型来帮助读者更好地理解中间的过程。
参考
- 神经网络量化简介
- Building a quantization paradigm from first principles
- Post Training Quantization General Questions
- 量化训练:Quantization Aware Training in Tensorflow(一)
- How to Quantize an MNIST network to 8 bits in Pytorch from scratch (No retraining required)
- Aggressive Quantization: How to run MNIST on a 4 bit Neural Net using Pytorch
- TensorFlow Lite 8-bit quantization specification
- Post-training quantization




想请教一下楼主,Scale=(Rmax-Rmin)/(Qmax-Qmin) ,只需要知道每一个feature map的Rmin,Rmax,这个Qmax,Qmin是不用计算的吧,直接和量化的位数有关系是吧?比如想把模型量化为uint8,则Qmax=255,Qmin=0;如果想量化为int8,则Qmax=127,Qmin=-128,这样理解对吗?谢谢
理解是对的
谢谢
还有就是在实际计算过程中,是如何去确定 M0 和 n 的呢?也是这么循环去计算的吗?这样相当于把一次浮点运算转换成了很多次定点运算,而且由于要进行误差比较,因此也会需要提前计算 M0 * P?
是不是在实际运算中,P是先不用乘进去,只要多次计算 M_0 * 2^(-n),这样子就只要多次整数移位 + 浮点数 M_0 * 2^(-n) 和 浮点数M的误差比较?
我的理解是, M_0 直接求最大值,等M_0 和后面的值相乘后再右移 n bit,这样可以最大程度保留精度。这点在英文原论文中比较明显,但作者也没有列公式
(q1-z1)(q2-z2)不是会超过int8的范围么?![[发呆]](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAEIAAABCCAYAAADjVADoAAALy0lEQVR4nO1bW2xUxxn+xkvWa6/Be/FissReo9oGgmCpxDVtwSLKAxEkUo0U1YRWlVDUi8QrjRBBSVQlSH1C6gvKQ0lq06hxJAoqqlAQQQ3mEgkcmgC2o/pSDMvi3bXxmrWxd/pwzszOzJlz9qyxSSLxSatzZnbOf/7zzT//zPwzAzzFU4ggT/Jl6XbUmW9dS4F1wl8xAAOmQl8CACiuBXdj6EnpNu9EpDuw0/zol8oINpfybB7IgOIGgDOE4oP5JGZeiOAfT7CvDAjMldw8RRcB3psPa5lTIkwC3ixW8x5fCM8srLP9P5fsLvquPMUxQnFwrgiZEyKKEeCLxOENrACJrgK8ftdy6VgCZPAyxtNfYSaX0pbJU7wTasOh2WlewGMRkW5HHSXYW0bwlvof//iGDY/zigKmspj8phOPHgxZSMlT9BNgX7ANJ2crftZEmCScLyNoEPN9kTi80Y0gi5fPVnRR0P7LyA6d0REya+uYFRHpDuykBB+KjtDjC8G/fNe8EiBhKgvafxljA6ek7DxFF6F4rVTfUTIRqQ68rTaF6mdbgOZtJbX/uQIdSyDb/YFkHXmKfkKxpRQySiJCR8Ki+BsFK5jKGmTYXR8Hogyd/J6zGL1zjhcvlQzXRKgkeHwh+ON7QXxVhUJOJExlreXUe13aqYwq5z8nZ02GKyLSHdhJCP7B0hYSdMrr4FSuFAIcyqh+w63PKCume7oddRQ4wtJaS3BDQrFyuv/UPBdlSMMGw2eZKCPYTAn2FlOtKBFqF2kh4fuI5m3wReI8WUbwVroDO50ecSTC9AsNLL0otuP7T4KJ8udb4fGFeJoSfMhnvxrYEpFuRx0I9rG0LxIHGyXS3Di/qvc0N457397hP7X8bK9uZKvP+eOFFlEGBCjBu3bfa+ssUx34SxnBr4DCYAk+Y/xEfFWguXF+7b2aQCY9jfvJGYucmogHALB+21Lts7o88Xrv2zvovzWmlQ0Ajc3lCCyuRGTpQq1s3P1Gcp6U4hXdUFxLRLoddaQMgyy9KLYDWPK8pDQAJG8/wJf/TttxqVW66ce1sgKi0kJeMQJU1EQ8nGxVtjjgylN0hdrwgvq8lgiLNcStTrf3agJ9PZNSXkW4HtXRJp4eHe4FADwc4ZxqFVahI1iVzeSLsgFg+2v1mg8awFjvxzyps4oF6jPpdtQRkwQA8NdayLOQsGT1i2jY/HP9VwFI3OzCf8//FQBwPzmDK2dv25KhklARrkdjyx74w1Fb2Xe/Ps8JOf3xoJWMUAweX4hbhRkxk4iwOkuCtezW4wvxJsGRy0gkLNvyuiMJAFC7YjNWtx5ARdhQ8H5yBr1XE9aCuYxEwpLVLyLeut+WBCa7sWUPlw0AV87etpSTKpRgn9qDWIigwJvsXhdFOn1iTFK0doW7MKQ/HEVjyx6e7uuZBHIZqcyVC4XBUTErU2XHW/dLRCdvP5ALBQpklgEBscLNvALS7agTo0zewArjxlRYFF4RrrdVNDsyjOzIsFbhZVte5+neG4KPyWW4Y6wI1yPSvKkk2QAkovtvjUm6wxeQBlkUaBWflX2E2ixCMUOQLwDkMsjcE/zCqi0WRfq7PsWpo29jPG2YfcvLrdj0xp+lMrUrNnN/0dcziaaVJskjHl6mOtpkaQ6Jm1344vj76Om+xGWvbj0glfOHo6gI1+PhyKBBKtPdJMRbWYccutm3virKlyxCZOmZhXUSCfAFkElPSx+kKvq3w7/jJADAuX924uLR31sIW7L6RTnDF0Dm3gRPqtaQHRnG3w//hpPAZP/ryG+tsoUK6r1hNj/2HUrzEP2E6iOa2Y230izDTEsxXRVfHH/fkscUVk25Ivgsv0+OeAxrE0hWraHv3EcSwQw93ZeQuNmlfa8F5neIw26xBchEEKx0J/XJQh0rSP+l70jpqkjMUZbYAYirbZyIdDvqpMWYgH2XpUN06XPa/KpgraWGVeWLQWeBDHZO1SU4a0Wn4SLYvEFXQ6tbD6AqWGvJ/9mONkseG3ECQCRsNLdAsOC31abU2LJHK7vl5VYLycmei/w+sLjS8kz5gqCY5K6g8Ha1x9AgEFzA/UTiZpfkMP3hKH79p9O43vlHDN/+HwDgJ7/4g8WpZkeGtUQGFlcC5kAt2XMRfqFr1sn+0ZoXEG/db5EjkVyRAlCt/RYVliG2E5piOfT1GNOTu1+ft3ykPxy1dJcqxBprbC7n98wyAODu9c8Qad5k6RqLyU7c7OIk10Q8QKU1YEy9UjyFe237ppERzHNi1LhWVkvNo7/rU0fFdIrevf4ZTzfFctI7RGL6zn1UkuzsyDAfnwDA+rXTsu4To8DEKKYm9KFLbhEUWMemojO5lDGHHzCaSVVwDWhlNTAxivVrgdNnTKswP8rNUFiceAGmNVSWGwpWGubbtLKcxzUejgyiu/Ow44RLJEEkTpRNxhMY16yKmeBemwDW+IMObAXbG1iB5MOQZYa4ZNUW7byDKSn6hcbm8oI1mATzKwpEM9nV0SZLU2Gykz0XJSuriXiwfu00pjI3Xa2qsyk5AfRrFnarz8xC7nlWaoMyYlenc4qcBOHDOWzI0MnWya+JeLCh8ba0tqHTX1kVeyfUhkOGRQjrFjwsBxhtyoZZttp95doC11GkdT8Nmp5cgY4UAL0DPkvwxw6NzeWIVV9z1JU1weytTwqxCdMiLL3GTC5VMNVQDN7KanijGzE1fEl6SS7ZjUcPhrB+7UsAgCvXDFEqKTURDxqWLzIJUEhgBGhIAAxn2hQzCNHFRGsiHgSCC9AUyyE7dBK5pCyfrcyL8yWkBrTWzu0v1YELbAouWQUTYkJkk7+MTde/I6hWKwWblZiHqH+eoj/UhmWA0H0S4D12P5NLIXvrE6OmhPk8APiX75Lm9blkN8i4Jtr0pDCVlUjwReKFShR1nxjFWPdRqRIJBZ+qciKCbThJKV5h6Zlcygh4svGEwKw3ulEafU5Op7lSTgrPGg5Lf9nEBX7v8YWMpqCADF6WgreAsQdLXA+VBlTBNpzMU0jz2rGBU/LgyoQYA8wlu+XVaaaoeC8u1qplil3VZ4XtAWINVwXXWPTExKi2FyFAp5jWDbHPAPKmsGziAvyBXXKpQNTcImrqNDEEL4tzqMv2Qg0avYw4zK3SXrdvRdEtBuookS5uhors0BlLXh7IhIqF80NtOJQ6Lu+PnMmlDKtQpua+SNzaXelqT7h+dW0AbnD68+ewfeu4oywR2oliZlg/HqI4oWbp5xqaghL7mu7u0YOhgsKAvLtFuNrFLVTweYe400aRxd8JJeJu6mc3ryAUB9U87eyTUByEsMgjQZgblC8Igk2bLMzbOMftW8fhZjMumRoARZWjkxXfyUOLgn465CmOhTSbRrQWEdyNoTzFMcsf4pxgYhS0yhosmSso02V3UPTTQWcNgMM0nFAczAMZyx8OjJOpce29039Oz9g9ry3r9ctDdY2OapcpwpaI4G4MmTvjASghLhu2RSVZjTKFqbfK1b34jHgVLcSWMFEvRUdzY5nWGoASY5bFwAdWJtgH6GpTR4aaVq/is+q7dFDik3DaUOZIhLj8Z9dm1W7LrracSBHfIRJiR4Iqwy7GKulMnD2089YhF7CLW+jMWtcc1LLsf7WcKkOt7WJQV7Y0/7uEzbjADmqbtmvjYr6dj1DvAbkZ8spQdStht689EcqyOR8qO4zupMeLeXlNvq6MXZO0WIRON1U/9ZsE2BNBcc2Spw6fiyk3B7AjUOss58UidAopH68OYd148rmCSrqWMEVfp4MtjnuxxagVYEyymAKT02ltfJBFu+fDOhjsjjY56We3m47BkQh1M3opEAmZnE5LCqr3dle1jO4Yk1vY7a9kKLo7X3dGQ0QeyBCKXzodbhNP9ekI0YE1MzbD1BFgngs9UuxYpZsjTu6OKRjnt94F0FxGsNnuYKrb446A/SDITY0zAti72SE7CIds8xT9AD4nQKebQ2/zeQC2FQSvzvUBWMzTqeAfwpHoEwAGfpBHop1g7vpXD8mLCn0nh+Sf4ilk/B8DFbYbPD00IAAAAABJRU5ErkJggg==)
实际计算的时候是拆成四个项来算,都是int32的加减
再乘以前面的scale就会重新回到int8范围
多谢大佬,请问有个小细节 “只要 M0P 的数值范围在 21(32-11) 个 bit 内”,请问这个地方是不是写错了,M_0P即使是23个比特,也仍然可以右移11个比特;是不是应该 初识的 M 应该在21个比特内,因为在计算过程中先先左移 n 个比特,这样如果超过21的比特,左移过程就会超限。
同样的疑问
时隔半年,再来看这篇帖子,终于知道这篇帖子的意义了.